数据被各行各业视为宝贵的资产,是推动业务增长和创新的关键。然而,随着数据量的快速增长和数据类型的多样化,如何高效地存储、处理和分析这些数据,成为了企业面临的一大挑战。在这样的背景下,“湖仓一体”(Lakehouse)作为一种新兴的数据架构模式,应运而生,为解决企业数据管理和分析难题提供了新的思路。
湖仓一体是什么?
湖(数据湖)仓(数据仓库)一体是一种新型的开放式架构,打通了数据仓库和数据湖,将数据仓库的高性能及管理能力与数据湖的灵活性融合了起来,底层支持多种数据类型并存,能实现数据间的相互共享,上层可以通过统一封装的接口进行访问,可同时支持实时查询和分析,为企业进行数据治理带来了更多的便利性。
湖仓一体可以解决什么样的问题?
一、数据孤岛与整合难题
在传统的数据架构中,数据仓库(Data Warehouse)和数据湖(Data Lake)各自扮演着不同的角色。数据仓库主要用于结构化数据的存储和分析,强调数据的准确性和一致性;而数据湖则侧重于存储海量、多样化的数据,包括半结构化和非结构化数据,强调数据的原始性和可扩展性。然而,这种分离的数据存储方式往往导致数据孤岛现象,即不同来源、不同格式的数据难以有效整合,影响了数据的全面性和可用性。
湖仓一体架构通过融合数据仓库和数据湖的优势,打破了这一壁垒。它允许在同一平台上同时处理结构化、半结构化和非结构化数据,实现了数据的无缝集成和统一管理。这种整合不仅简化了数据流程,减少了数据迁移和转换的成本,还促进了跨部门、跨系统的数据共享,为数据驱动的决策提供了坚实的基础。
二、数据质量与治理挑战
数据质量是数据价值实现的前提。在数据湖环境中,由于数据来源广泛、格式多样,数据质量问题尤为突出,如数据重复、缺失、错误等,这些都直接影响到数据分析的准确性和可靠性。同时,数据治理也是一项复杂而艰巨的任务,需要确保数据的合规性、安全性和可访问性。
湖仓一体架构通过引入数据治理框架,如数据分类、数据清洗、数据脱敏、权限管理等措施,有效提升了数据质量。它支持在数据摄入阶段就进行数据校验和清洗,确保数据的一致性和准确性;同时,通过元数据管理和数据血缘追踪,增强了数据的可追溯性和透明度,为数据治理提供了强有力的支持。此外,湖仓一体还集成了安全控制机制,如数据加密、访问控制等,保障了数据的安全性和隐私保护。
三、实时分析与响应需求
在快速变化的市场环境中,企业对于数据的实时性和敏捷性要求越来越高。传统的数据仓库虽然能够提供高性能的查询和分析能力,但往往难以应对大规模数据的实时处理需求。而数据湖虽然具备处理海量数据的能力,但在实时分析方面则显得力不从心。
湖仓一体架构通过优化数据处理引擎,如采用流处理技术和批处理技术的结合,实现了数据的实时摄入、处理和分析。这意味着企业可以在数据产生的瞬间就能获取到分析结果,从而更快地做出决策,响应市场变化。此外,湖仓一体还支持交互式查询和自助式分析,使得业务人员能够直接访问和分析数据,提高了数据分析的效率和灵活性。
四、成本与资源优化
随着数据量的增长,数据存储和处理成本也在不断增加。传统的数据架构往往需要根据不同的数据类型和分析需求,部署多个独立的存储和处理系统,这不仅增加了硬件和软件的投入,还带来了运维管理的复杂性。
湖仓一体架构通过统一的底层存储和计算资源,实现了资源的有效整合和优化。它支持按需扩展,能够根据数据量和处理需求动态调整资源分配,降低了成本。同时,湖仓一体还利用先进的压缩技术和数据去重技术,减少了存储空间的占用,进一步降低了存储成本。此外,通过智能化的资源调度和负载均衡机制,湖仓一体还提高了计算资源的利用率,确保了系统的高性能和稳定性。
湖仓一体服务商介绍
北京飞轮数据科技有限公司(SelectDB)是一家基于开源分析型数据库 Apache Doris 的商业化公司,由 Apache Doris 原创团队于2022年1月创建,公司总部位于北京,面向全球提供实时数据仓库的产品与解决方案,满足各类场景的实时数据分析需求。其中主要的四大场景为:实时报表与分析、用户画像与行为分析、湖仓一体(下图为 SelectDB 的湖仓一体解决方案)、日志存储与分析。
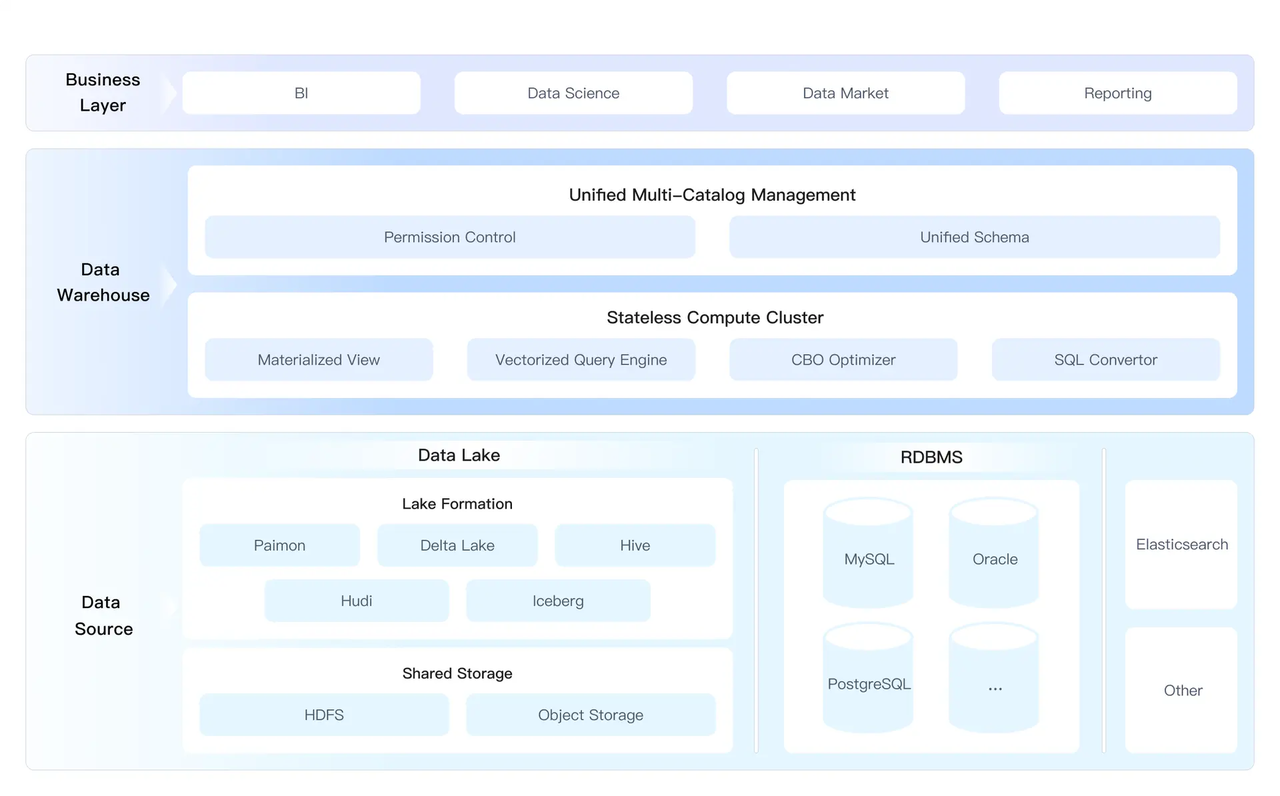
湖仓一体再进化
尽管 Apache Doris 定位于实时数据仓库,在以往版本中一直不拘于数据仓库的能力边界,在湖仓一体方向持续发力。而 3.0 版本是 Apache Doris 在湖仓一体路线上的重要里程碑版本,从 3.0 版本开始,Apache Doris 在湖仓一体场景的能力臻于完善。3.0 版本具体优化:
湖仓查询加速
在 3.0 版本中,我们重点针对用户实际生产环境中的湖仓查询加速场景进行了优化,包括:
1、更精细的任务拆分策略: 通过对一致性哈希算法的调整以及引入任务分片权重机制,确保各个节点的查询负载均衡。
2、面向多分区、多文件场景的调度优化: 在大量文件(100 万+)场景下,通过异步、分批获取文件分片的方式,显著降低查询耗时(100s -> 10s),并降低 FE 内存压力。
联邦分析 - 更丰富的数据源连接器
在之前的版本中,Apache Doris 已经支持了 10 余种主流湖、仓、关系型数据库的连接器。在 3.0 版本中,我们引入了 Trino Connector 兼容框架,极大扩展了 Apache Doris 可连接的数据源。借助该框架,仅需简单适配,用户即可通过 Doris 访问对应的数据源,并利用 Doris 的极速计算引擎进行数据分析。
目前 Doris 已完成 Delta Lake、Kudu、BigQuery、Kafka、TPCH、TPCDS 等多种 Connector 的适配,也欢迎所有开发者参考开发指南,为 Apache Doris 适配更多数据源。
数据湖构建
在 3.0 版本中,Apache Doris 增加了 Hive、Iceberg 数据写回功能。写回功能支持用户直接通过 Doris 创建 Hive、Iceberg 表,并将数据写入到表中。该功能使得 Apache Doris 在湖仓数据处理能力上形成闭环,用户可以在 Apache Doris 中完成多个数据源之间的数据分析、共享、处理、存储操作。
在后续的迭代版本中,Apache Doris 将进一步完善对数据湖表格式的支持以及存储 API 开放性。
