
在实时数据仓库建设或迁移的过程中,用户必须考虑如何高效便捷将关系数据库数据同步到实时数仓中来,Apache Doris 用户也面临这样的挑战。而对于从 Oracle 到 Doris 的数据同步,通常会用到以下两种常见的同步方式:
OGG/XStream/LogMiner 工具: 通过该方式先将数据同步到 Kafka 中,然后通过 Routine Load 消费 Kafka 中的数据进行实时同步。这种方式的同步链路相对较长,特别是在上游数据表较多的情况下,需要手动创建大量的 Routine Load 作业,同步流程不仅繁琐,也给用户增加了较大的使用及维护压力。
FlinkCDC: 该方式虽然可以直接将上游数据同步到 Doris 中,并在一定程度上缩短了同步链路,实际在使用过程中还会遇到以下问题:
- 数据同步时,需要在 Flink 中对每张表手动配置参数及字段映射,尤其是在多表或整库同步场景中,不仅带来大量配置工作量,还增加了 FlinkSQL 脚本的维护成本。
- 数据同步时,需要事先在 Doris 中手动逐个创建表,而面对数量庞大的上游表时,手动创建表不仅耗费时间,而且工作效率很低,间接影响数据同步的效率。
- 由于每张 Source 表都会使用同一个链接,因此在整库同步时会给源端造成很大的链接压力。
为了解决上述问题,在新版本的 Doris-Flink-Connector 中,我们实现了 FlinkCDC 的 Datastream API 集成,无需提前在 Doris 中创建表以及映射关系,仅仅通过简单的参数配置就能一键完成从 Oracle 等关系型数据库到 Apache Doris 的整库数据同步。
此外,Doris-Flink-Connector 也可以一键实现万表 MySQL 整库同步至 Apache Doris 中来,具体使用可参考:一键实现万表 MySQL 整库同步至 Apache Doris
同步流程 & 实战演示
在进行整库同步前,我们先了解一下具体同步流程:

- 在启动 Flink 任务之前,Doris-Flink-Connector 会自动读取需要同步的 Oracle 表的元数据信息,并自动在 Doris 中创建相应的表。
- 通过 FlinkCDC 提供的 OracleSource 功能,能够从 Oracle 数据库中读取数据,并将其传递到下游进行处理。
- 通过 Flink 的侧输出流功能,根据自定义规则将数据分流到不同的 Doris Sink 中,并同步到 Doris 中来。
通过以上简单操作,即可实现上游 Oracle 数据库的整库数据实时数据接入到 Apache Doris 中。接下来我们通过一个实际案例来详细说明具体的操作步骤:
01 Oracle 环境准备
# 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
# 启动镜像
docker run -it -d \
--privileged \
-p 1521:1521 \
--name oracle11g \
-e ORACLE_ALLOW_REMOTE=true \
-v /mnt/disk1/oracle:/data/oracle \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
# 进入容器
docker exec -it oracle11g bash
Oracle 归档日志(Binlog)配置:启动归档日志时,需对日志大小和存放地址进行设置,设置完成需进行重启。该步骤完成后才可进行后续增量数据的同步。
# 进入SQL命令行
[oracle@ef6d9de18e59 ~]$ sqlplus /nolog
SQL> conn /as sysdba
Connected.
SQL> alter system set db_recovery_file_dest_size = 10G;
System altered.
SQL> alter system set db_recovery_file_dest = '/home/oracle/oracle-data' scope=spfile;
System altered.
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 1603411968 bytes
Fixed Size 2213776 bytes
Variable Size 402655344 bytes
Database Buffers 1174405120 bytes
Redo Buffers 24137728 bytes
Database mounted.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
# 检查日志归档是否开启
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 1
Next log sequence to archive 1
Current log sequence 1
# 启用补充日志记录
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Database altered.
#创建用户
CREATE USER admin IDENTIFIED BY admin123;
GRANT dba TO admin;
数据准备
[oracle@ef6d9de18e59 ~]$ sqlplus admin/admin123
SQL> CREATE TABLE PERSONS(
ID NUMBER(10),
NAME VARCHAR2(128) NOT NULL,
PRIMARY KEY(ID)
);
Table created.
SQL> INSERT INTO "PERSONS" VALUES (1, 'zhangsan');
SQL> INSERT INTO "PERSONS" VALUES (2, 'lisi');
SQL> INSERT INTO "PERSONS" VALUES (3, 'wangwu');
SQL> CREATE TABLE PERSONS_1(
ID NUMBER(10),
NAME VARCHAR2(128) NOT NULL,
PRIMARY KEY(ID)
);
Table created.
SQL> INSERT INTO "PERSONS_1" VALUES (1, 'zhangsan');
SQL> INSERT INTO "PERSONS_1" VALUES (2, 'lisi');
SQL> INSERT INTO "PERSONS_1" VALUES (3, 'wangwu');
02 Flink 环境配置
将 FlinkCDC-Oracle 的依赖和 Doris-Flink-Connector 包放到 Flink 的 lib 目录下,同时启动 Flink 集群。
# 下载相关依赖
wget https://repo.maven.apache.org/maven2/com/ververica/flink-sql-connector-oracle-cdc/2.3.0/flink-sql-connector-oracle-cdc-2.3.0.jar
wget https://repository.apache.org/content/repositories/snapshots/org/apache/doris/flink-doris-connector-1.16/1.5.0-SNAPSHOT/flink-doris-connector-1.16-1.5.0-20230811.065053-1.jar -O flink-doris-connector-1.16-1.5.0-SNAPSHOT.jar
# 启动Flink集群
bin/start-cluster.sh
03 一键提交整库同步作业
本次同步以 PERSON 开头的所有的表。
<FLINK_HOME>/bin/flink run \
-Dexecution.checkpointing.interval=10s \
-Dparallelism.default=1 \
-c org.apache.doris.flink.tools.cdc.CdcTools \
./lib/flink-doris-connector-1.16-1.5.0-SNAPSHOT.jar \
oracle-sync-database \
--database test_db \
--oracle-conf hostname=127.0.0.1 \
--oracle-conf port=1521 \
--oracle-conf username=admin \
--oracle-conf password=admin123 \
--oracle-conf database-name=HELOWIN \
--oracle-conf schema-name=ADMIN \
--including-tables "PERSONS.*" \
--sink-conf fenodes=127.0.0.1:8030 \
--sink-conf username=root \
--sink-conf password=\
--sink-conf jdbc-url=jdbc:mysql://127.0.0.1:9030 \
--sink-conf sink.label-prefix=label \
--table-conf replication_num=1
提交成功后,可以在 FlinkWeb 上看到该同步任务的状态。
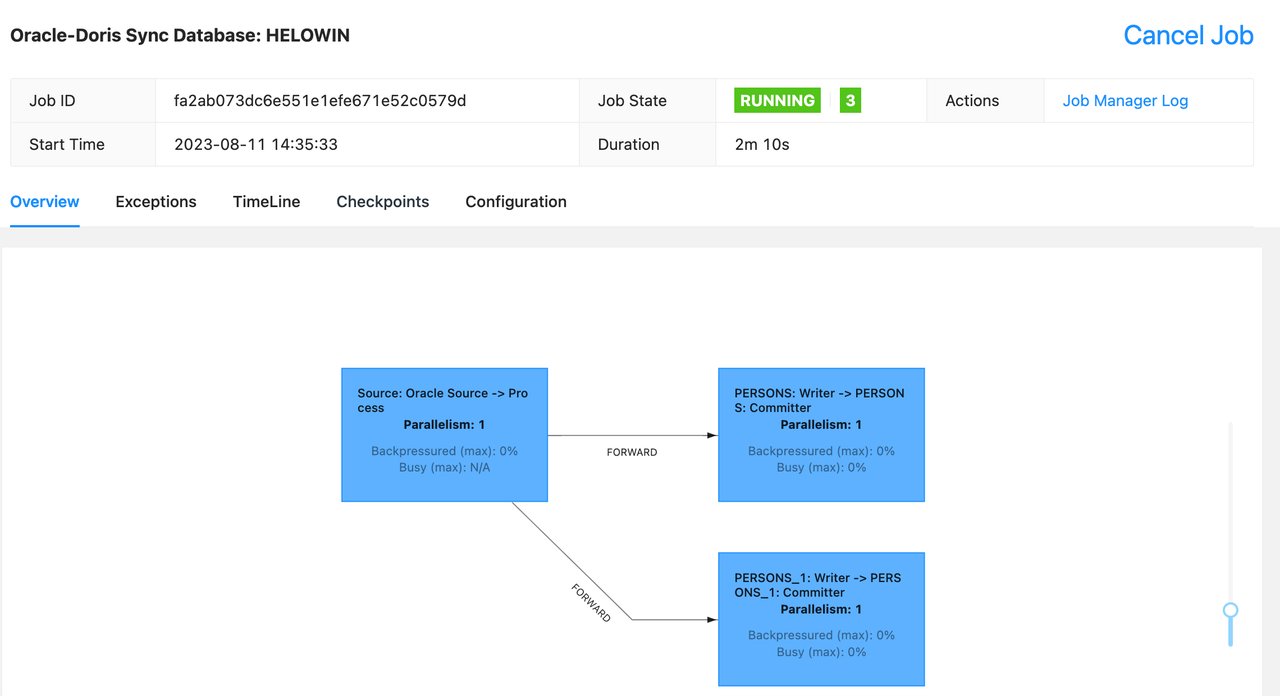
进入 Doris 可以查看自动创建的表以及同步成功的全量数据。
mysql> use test_db;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-------------------+
| Tables_in_test_db |
+-------------------+
| PERSONS |
| PERSONS_1 |
+-------------------+
2 rows in set (0.00 sec)
mysql> select * from PERSONS;
+------+----------+
| ID | NAME |
+------+----------+
| 2 | lisi |
| 3 | wangwu |
| 1 | zhangsan |
+------+----------+
3 rows in set (0.01 sec)
mysql> select * from PERSONS_1;
+------+----------+
| ID | NAME |
+------+----------+
| 2 | lisi |
| 3 | wangwu |
| 1 | zhangsan |
+------+----------+
3 rows in set (0.01 sec)
在 Oracle 中模拟实时增删改数据
INSERT INTO PERSONS VALUES(4,'doris');
UPDATE PERSONS SET name = 'zhangsan-update' WHERE ID =1;
DELETE PERSONS WHERE ID =2;
在 Doris 中进行验证,可以确认增量数据已经成功同步。
mysql> select * from PERSONS;
+------+-----------------+
| ID | NAME |
+------+-----------------+
| 1 | zhangsan-update |
| 4 | doris |
| 3 | wangwu |
+------+-----------------+
3 rows in set (0.01 sec)
通过以上操作,成功实现将 Oracle 中数据整库同步到 Doris 中,同时也实现了上游全量与增量数据的自动接入。
实际使用反馈
原先将 Oracle 数据同步到 Doris 中时,需要手动创建 Source 和 Sink 表,而使用 Doris-Flink-Connector 后可以实现多表、整库数据一键同步,极大简化了开发流程,该工具还能实现字段类型自动转换,数据同步更加简单便捷。
—— 远景动力 资深大数据工程师 孙全隆
在使用 Doris-Flink-Connector 之前,我们一般是通过 DataX 定时从业务系统中抽取数据,当进行全量同步时,抽取数据会对业务系统造成一定的压力,且该方式只能做到小时级的同步。期间我们也尝试了 FlinkCDC,该方式虽然可以实现数据实时写入 Doris ,但每个表都需要手动创建新任务,配置工作量大且会浪费服务器资源。而 Doris-Flink-Connector 可以实现一键化脚本操作,为我们减少了繁杂的手工配置流程,高效稳定的实现了整库数据快速同步。
—— 郑煤机数耘科技 资深大数据工程师 杨开元
Doris-Flink-Connector 一键操作即可快速实现 Oracle 数据整库同步到 Doris,节省了手动配置以及编写复杂同步代码的步骤,避免了手动同步中可能出现数据不一致的问题。不仅能提高数据的准确性和可靠性,也极大提升了工作的效率。
—— 海程邦达 资深大数据工程师 王新
在实时数仓的建设过程中,对于 ODS 贴源数据层的同步需求,Doris-Flink-Connector 能够很好的解决全量数据、增量数据、增量表、表结构变更自动监听。同时它也对 Stream Load 逻辑进行了优化,可以避免频繁对空数据进行 Load,减轻了数据库压力。此外,Doris-Flink-Connector 能够帮助我们节省大量 Flink 集群资源,特别是业务变更频繁时期,能很好及时的同步上游状态,确保上下游数据的一致性。
——旺小宝 数据架构师 米华军
我们在 MySQL 和 Orcale 两个场景下均进行了全量 + 增量的尝试,Doris-Flink-Connector 是真正的拆箱即用,真正实现了一键式操作、无感知建表,这为开发人员节省了不少时间成本,同时在使用期间遇到问题,SelectDB 技术同学的响应速度非常给力,帮助我们快速推进数据同步工作。
—— 博思软件 资深大数据开发工程师 刘工
总结
Doris-Flink-Connector 通过集成 FlinkCDC,能够将上游 Oracle 数据库中的数据快速同步到 Doris 中。特别是在整库同步场景中,用户只需执行一键导入命令,即可快速将整个数据库的全量和增量数据导入到 Doris 中。这一功能的引入大大降低了数据同步的门槛,使数据同步变得更加简单高效。


