实时数仓架构是一种数据仓库架构,主要设计用于实时或近实时地处理和分析数据。这种架构可以极大地提高数据的处理速度和响应速度,使得企业能够更快地获取业务洞察并做出决策。
实时数仓架构通常包括以下几个关键组件:
数据源: 这是实时数仓架构的起点,可以包括各种在线交易系统、业务数据库、日志、传感器数据等。数据源可以是结构化的,如关系型数据库中的数据表,也可以是非结构化的,如日志文件或社交媒体数据流。
数据采集与传输: 这一层负责实时地从数据源捕获数据,并将其传输到实时数仓中。这通常涉及使用消息队列(如Kafka)或流处理工具(如Flink或Storm)来实现。这些工具可以确保数据在传输过程中的可靠性和一致性。
实时数仓存储: 实时数仓存储层负责存储和处理实时数据流。这里可能使用到列式存储引擎(如ClickHouse、Greenplum、Apache Doris等),这些引擎通常针对高速写入和复杂查询进行了优化。此外,实时数仓还可能包含实时计算层,用于对数据进行预处理、聚合和转换,以便后续的分析和查询。
实时分析: 在实时数仓中,数据可以立即被用于各种实时分析任务,如仪表盘展示、报警触发、预测建模等。这些分析任务通常由实时分析引擎(如Presto、Impala、Apache Doris等)或机器学习平台来执行。
数据服务: 实时数仓架构的最后一部分通常是一个数据服务层,它向外部应用或用户提供数据访问接口。这些接口可以是RESTful API、SQL查询接口或其他形式的数据服务。
下图是实时数仓的经典架构:
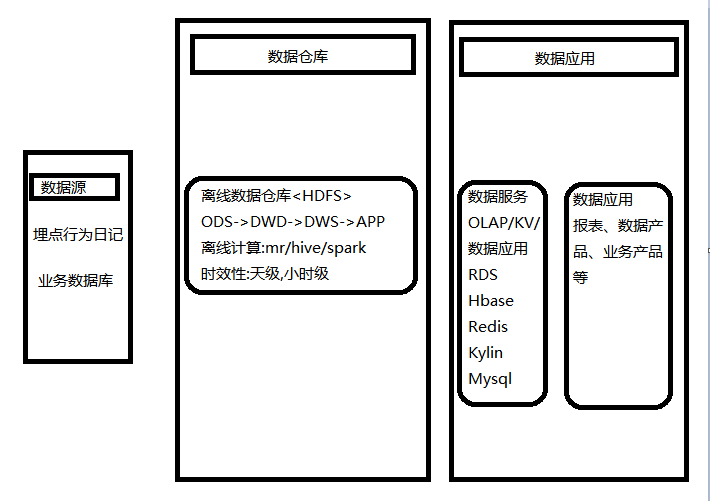
这个架构中,中间数据仓库环节有两个部分,一个是离线的数据仓库,一个是实时的数据仓库。运维两套(实时计算和离线计算)引擎,在代码层面需要去实现实时和离线的业务代码。另外在合并的时候,需要保证实时和离线的数据一致性,所以但凡代码要做变更,就需要去做大量的这种实时离线数据的对比和校验。其实这对于不管是资源还是运维成本来说都是比较高的。这是 Lamda 架构上比较明显和突出的一个问题。因此就产生了 Kappa 结构。
Kappa 架构在这一块的思路是:首先要准备好一个能够存储历史数据的消息队列,比如 Kafka,并且这个消息对列是可以支持你从某个历史的节点重新开始消费的。接着需要新起一个任务,从原来比较早的一个时间节点去消费 Kafka 上的数据,然后当这个新的任务运行的进度已经能够和现在的正在跑的任务齐平的时候,你就可以把现在任务的下游切换到新的任务上面,旧的任务就可以停掉,并且原来产出的结果表也可以被删掉。
随着我们现在实时 OLAP 技术的一些提升,有一个新的实时架构被提了出来,这里暂且称为实时 OLAP 变体。
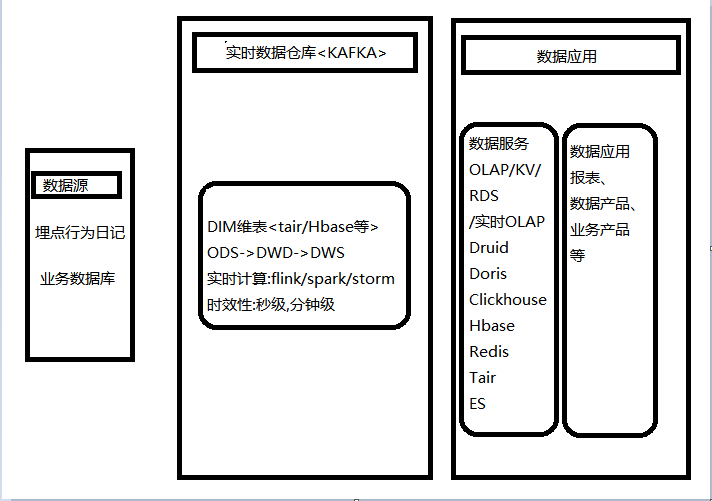
这个思路是把大量的聚合、分析、计算由实时 OLAP 引擎来承担。在实时数仓计算的部分,不需要做的特别重,尤其是聚合相关的一些逻辑,然后这样就可以保障在数据应用层能灵活的面对各种业务分析的需求变更,整个架构更加灵活。
