导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 Apache Doris 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。
杭银消费金融股份有限公司,成立于 2015 年 12 月,是杭州银行牵头组建的浙江省首家持牌消费金融公司,经过这几年的发展,在 2022 年底资产规模突破 400 亿,服务客户数超千万。公司秉承“数字普惠金融”初心,坚持服务传统金融覆盖不充分的、具有消费信贷需求的客户群体,以“数据、场景、风控、技术”为核心,依托大数据、人工智能、云计算等互联网科技,为全国消费者提供专业、高效、便捷、可信赖的金融服务。
业务需求
杭银消金业务模式是线上业务结合线下业务的双引擎驱动模式。为更好的服务用户,运用数据驱动实现精细化管理,基于当前业务模式衍生出了四大类的业务数据需求:
- 预警类:实现业务流量监控,主要是对信贷流程的用户数量与金额进行实时监控,出现问题自动告警。
- 分析类:支持查询统计与临时取数,对信贷各环节进行分析,对审批、授信、支用等环节的用户数量与额度情况查询分析。
- 看板类:打造业务实时驾驶舱与 T+1 业务看板,提供内部管理层与运营部门使用,更好辅助管理进行决策。
- 建模类:支持多维模型变量的建模,通过算法模型回溯用户的金融表现,提升审批、授信、支用等环节的模型能力。
数据架构 1.0
为满足以上需求,我们采用 Greenplum + CDH 融合的架构体系创建了大数据平台 1.0 ,如下图所示,大数据平台的数据源均来自于业务系统,我们可以从数据源的 3 个流向出发,了解大数据平台的组成及分工:
- 业务系统的核心系统数据通过 CloudCanal 实时同步进入 Greenplum 数仓进行数据实时分析,为 BI 报表,数据大屏等应用提供服务,部分数据进入风控集市 Hive 中,提供查询分析和建模服务。
- 业务系统的实时数据推送到 Kafka 消息队列,经 Flink 实时消费写入 ES,通过风控变量提供数据服务,而 ES 中的部分数据也可以流入 Hive 中,进行相关分析处理。
- 业务系统的风控数据会落在 MongoDB,经过离线同步进入风控集市 Hive,Hive 数仓支撑了查询平台和建模平台,提供风控分析和建模服务。
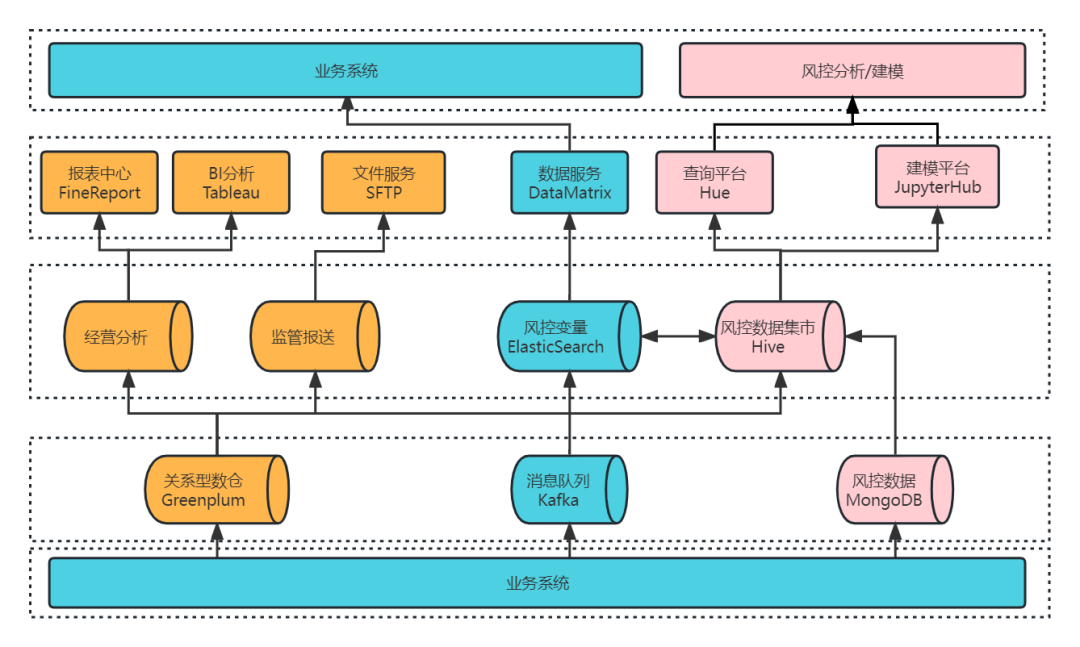
我们将 ES 和 Hive 共同组成了风控数据集市,从上述介绍也可知,四大类的业务需求基本都是由风控数据集市来满足的,因此我们后续的改造升级主要基于风控数据集市来进行。在这之前,我们先了解一下风控数据集市 1.0 是如何来运转的。
风控数据集市 1.0
风控数据集市原有架构是基于 CDH 搭建的,由实时写入和离线统计分析两部分组成,整个架构包含了 ES、Hive、Greenplum 等核心组件,风控数据集市的数据源主要有三种:通过 Greenplum 数仓同步的业务系统数据、通过 MongoDB 同步的风控决策数据,以及通过 ES 写入的实时风控变量数据。
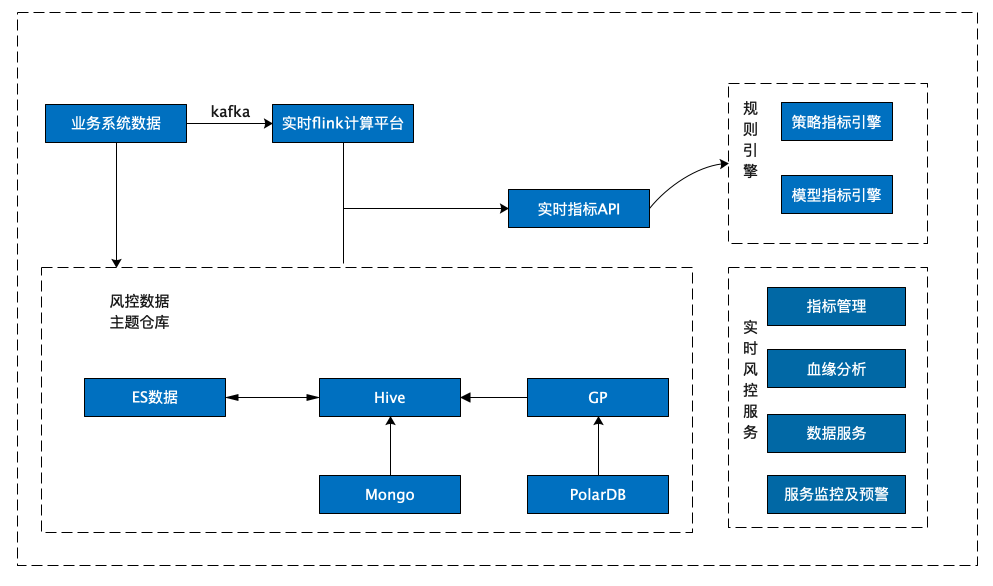
实时流数据: 采用了 Kafka + Flink + ES 的实时流处理方式,利用 Flink 对 Kafka 的实时数据进行清洗,实时写入ES,并对部分结果进行汇总计算,通过接口提供给风控决策使用。
离线风控数据: 采用基于 CDH 的方案实现,通过 Sqoop 离线同步核心数仓 GP 上的数据,结合实时数据与落在 MongoDB 上的三方数据,经数据清洗后统一汇总到 Hive 数仓进行日常的跑批与查询分析。
需求满足情况:
在大数据平台 1.0 的的支持下,我们的业务需求得到了初步的实现:
- 预警类:基于 ES + Hive 的外表查询,实现了实时业务流量监控;
- 分析类:基于 Hive 实现数据查询分析和临时取数;
- 看板类:基于 Tableau +Hive 搭建了业务管理驾驶舱以及T+1 业务看板;
- 建模类:基于 Spark+Hive 实现了多维模型变量的建模分析;
受限于 Hive 的执行效率,以上需求均在分钟级别返回结果,仅可以满足我们最基本的诉求,而面对秒级甚至毫秒级的分析场景,Hive 则稍显吃力。
存在的问题:
- 单表宽度过大,影响查询性能。风控数据集市的下游业务主要以规则引擎与实时风控服务为主,因规则引擎的特殊性,公司在数据变量衍生方面资源投入较多,某些维度上的衍生变量会达到几千甚至上万的规模,这将导致 Hive 中存储的数据表字段非常多,部分经常使用的大宽表字段数量甚至超过上千,过宽的大宽表非常影响实际使用中查询性能。
- 数据规模庞大,维护成本高。 目前 Hive 上的风控数据集市已经有存量数据在百 T 以上,面对如此庞大的数据规模,使用外表的方式进行维护成本非常高,数据的接入也成为一大难题。
- 接口服务不稳定。 由风控数据集市离线跑批产生的变量指标还兼顾为其他业务应用提供数据服务的职责,目前 Hive 离线跑批后的结果会定时推送到 ES 集群(每天更新的数据集比较庞大,接口调用具有时效性),推送时会因为 IO 过高触发 ES 集群的 GC 抖动,导致接口服务不稳定。
除此之外,风控分析师与建模人员一般通过 Hive & Spark 方式进行数据分析建模,这导致随着业务规模的进一步增大,T+1 跑批与日常分析的效率越来越低,风控数据集市改造升级的需求越发强烈。
技术选型
基于业务对架构提出的更高要求,我们期望引入一款强劲的 OLAP 引擎来改善架构,因此我们于 2022 年 9 月份对 ClickHouse 和 Apache Doris 进行了调研,调研中发现 Apache Doris 具有高性能、简单易用、实现成本低等诸多优势,而且 Apache Doris 1.2 版本非常符合我们的诉求,原因如下:
宽表查询性能优异:从官方公布的测试结果来看,1.2 Preview 版本在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能提升了 11 倍以上,多个场景性能得到飞跃性提升。
便捷的数据接入框架以及联邦数据分析能力: Apache Doris 1.2 版本推出的 Multi Catalog 功能可以构建完善可扩展的数据源连接框架,便于快速接入多类数据源,提供基于各种异构数据源的联邦查询和写入能力。 目前 Multi-Catalog 已经支持了 Hive、Iceberg、Hudi 等数据湖以及 MySQL、Elasticsearch、Greenplum 等数据库,全面覆盖了我们现有的组件栈,基于此能力有希望通过 Apache Doris 来打造统一数据查询网关。
生态丰富: 支持 Spark Doris Connector、Flink Doris Connector,方便离线与实时数据的处理,缩短了数据处理链路耗费的时间。
社区活跃: Apache Doris 社区非常活跃,响应迅速,并且 SelectDB 为社区提供了一支专职的工程师团队,为用户提供技术支持服务。
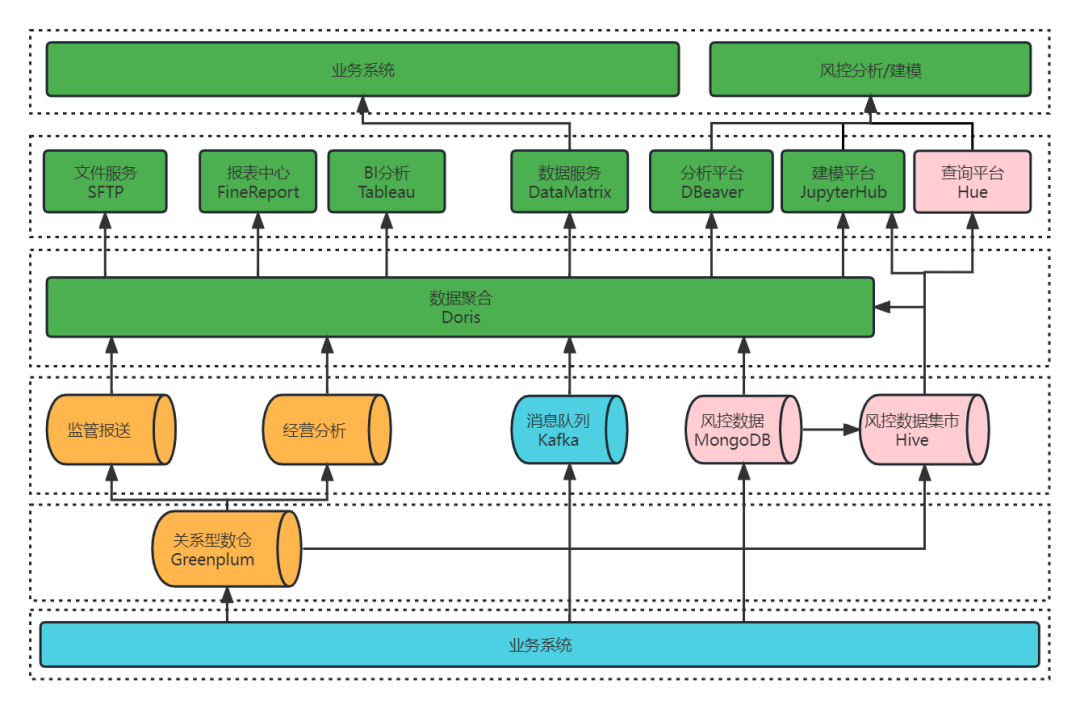
数据架构 2.0
风控数据集市 2.0
基于对 Apache Doris 的初步的了解与验证,22 年 10 月在社区的支持下我们正式引入 Apache Doris 1.2.0 Preview 版本作为风控数据集市的核心组件,Apache Doris 的 Multi Catalog 功能助力大数据平台统一了 ES、Hive、Greenplum 等数据源出口,通过 Hive Catalog 和 ES Catalog 实现了对 Hive & ES 等多数据源的联邦查询,并且支持 Spark-Doris-Connector,可以实现数据 Hive 与 Doris 的双向流动,与现有建模分析体系完美集成,在短期内实现了性能的快速提升。
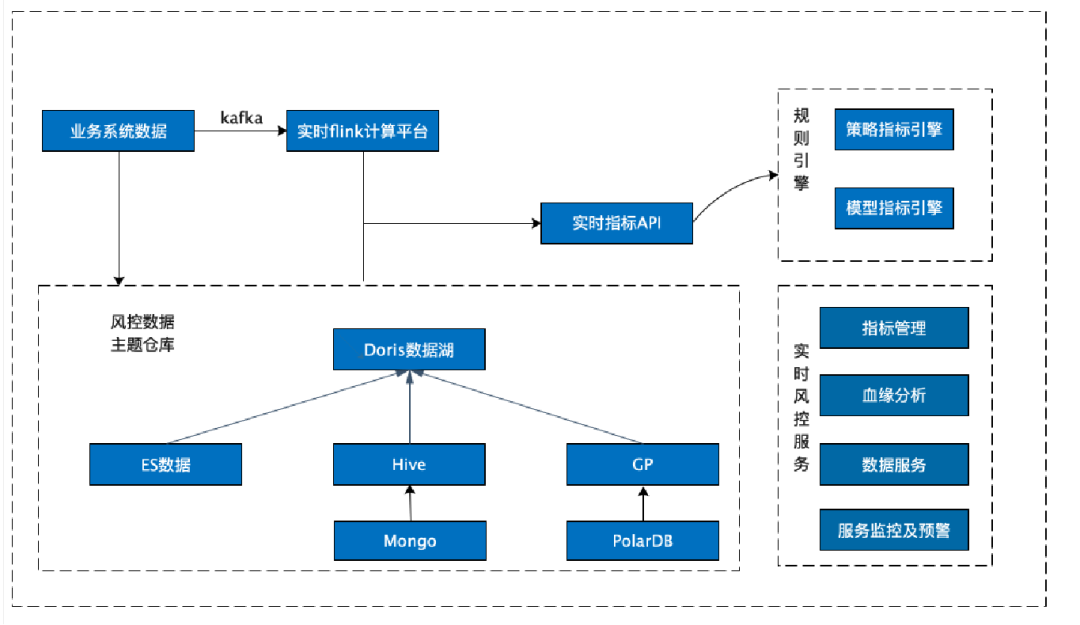
大数据平台 2.0
风控数据集市调整优化之后,大数据平台架构也相应的发生了变化,如下图所示,仅通过 Doris 一个组件即可为数据服务、分析平台、建模平台提供数据服务。
在最初进行联调适配的时候,Doris 社区和 SelectDB 支持团队针对我们提出的问题和疑惑一直保持高效的反馈效率,给于积极的帮助和支持,快速帮助我们解决在生产上遇到的问题。
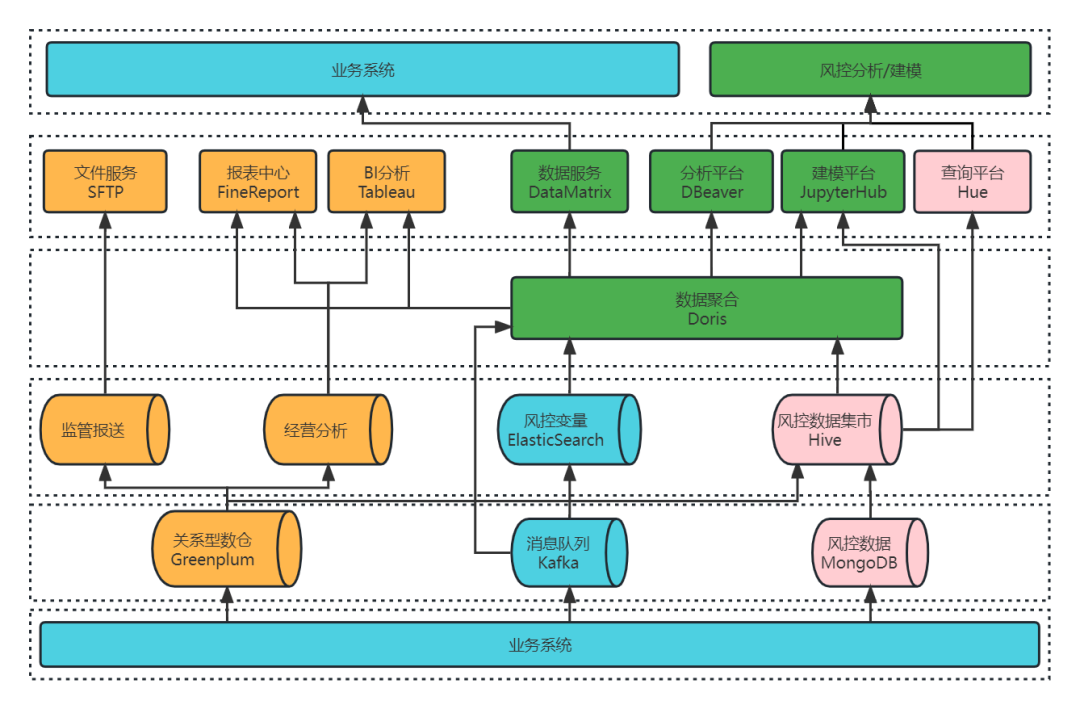
需求实现情况:
在大数据平台 2.0 的加持下,业务需求实现的方式也发生了变更,主要变化如下所示
- 预警类:基于 ES Catalog+ Doris 实现了对实时数据的查询分析。在架构 1.0 中,实时数据落在 ES 集群上,通过 Hive 外表进行查询分析,查询结果以分钟级别返回;而在 Doris 1.2 集成之后, 使用 ES Catalog 访问 ES,可以实现对 ES 数据秒级统计分析。
- 分析类:基于 Hive Catalog + Doris 实现了对现有风控数据集市的快速查询。目前 Hive 数据集市存量表在两万张左右,如果通过直接创建 Hive 外部表的方式,表结构映射关系的维护难度与数据同步成本使这一方式几乎不可能实现。而 Doris 1.2 的 Multi Catalog 功能则完美解决了这个问题,只需要创建一个 Hive Catalog,就能对现有风控数据集市进行查询分析,既能提升查询性能,还减少了日常查询分析对跑批任务的资源影响。
- 看板类:基于 Tableau + Doris 聚合展示业务实时驾驶舱和 T+1 业务看板,最初使用 Hive 时,报表查询需要几分钟才能返回结果,而 Apache Doris 则是秒级甚至是毫秒级的响应速度。
- 建模类:基于 Spark+Doris 进行聚合建模。利用 Doris1.2 的 Spark-Doris-Connector功 能,实现了 Hive 与 Doris 数据双向同步,满足了 Spark 建模平台的功能复用。同时增加了 Doris 数据源,基础数据查询分析的效率得到了明显提升,建模分析能力的也得到了增强。
在 Apache Doris 引入之后,以上四个业务场景的查询耗时基本都实现了从分钟级到秒级响应的跨越,性能提升十分巨大。
生产环境集群监控
为了快速验证新版本的效果,我们在生产环境上搭建了两个集群,目前生产集群的配置是 4 个 FE + 8个 BE,单个节点是配置为 64 核+ 256G+4T,备用集群为 4 个 FE + 4 个 BE 的配置,单个节点配置保持一致。
集群监控如下图所示:
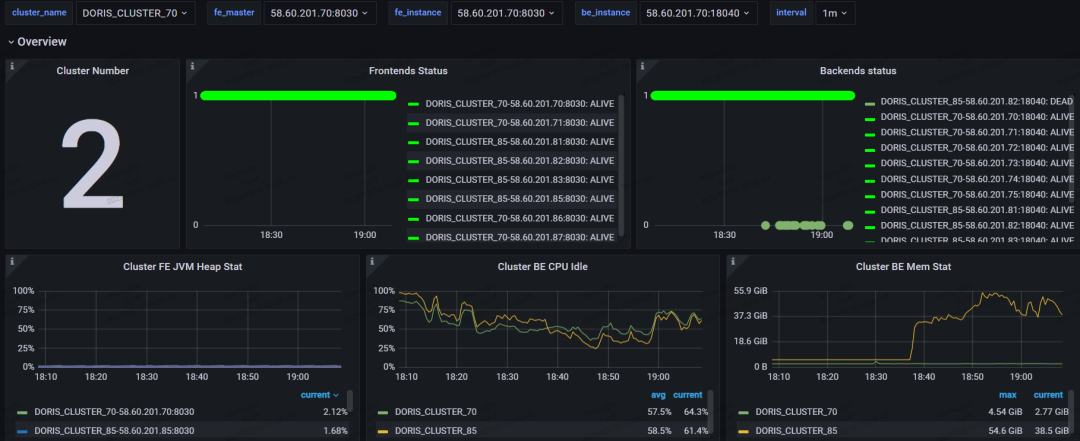
可以看出,Apache Doris 1.2 的查询效率非常高,原计划至少要上 10 个节点,而在实际使用下来,我们发现当前主要使用的场景均是以 Catalog 的方式查询,因此集群规模可以相对较小就可以快速上线,也不会破坏当前的系统架构,兼容性非常好。
01 数据集成方案
前段时间,Apache Doris 1.2.2 版本已经发布,为了更好的支撑应用服务,我们使用 Apache Doris 1.2.2 与 DolphinScheduler 3.1.4 调度器、SeaTunnel 2.1.3 数据同步平台等开源软件实现了集成,以便于数据定时从 Hive 抽取到 Doris 中。整体的数据集成方案如下:
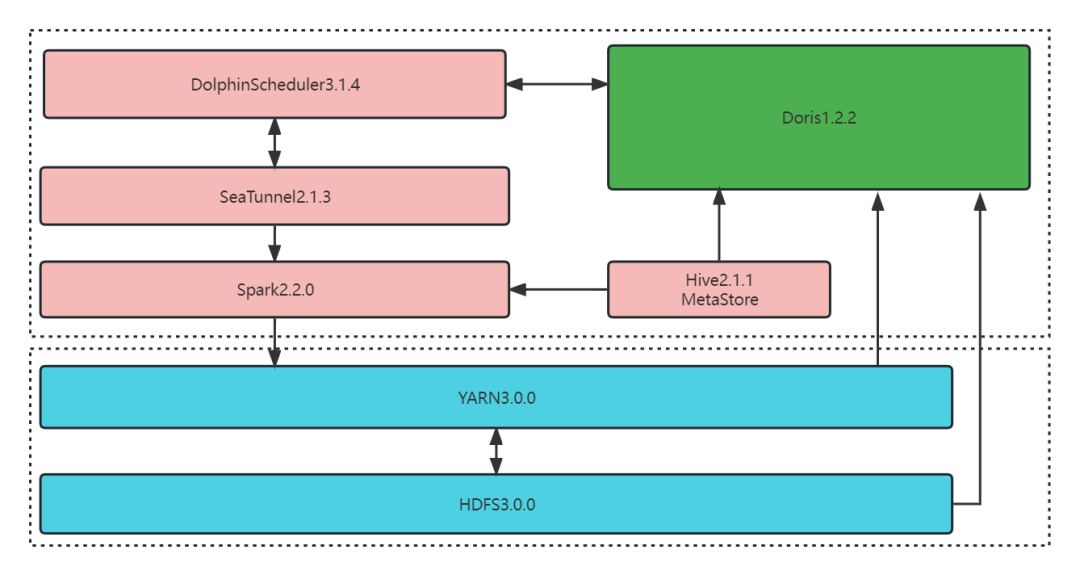
在当前的硬件配置下,数据同步采用的是 DolphinScheduler 的 Shell 脚本模式,定时调起 SeaTunnel 的脚本,数据同步任务的配置文件如下:
env{
spark.app.name = "hive2doris-template"
spark.executor.instances = 10
spark.executor.cores = 5
spark.executor.memory = "20g"
}
spark {
spark.sql.catalogImplementation = "hive"
}
source {
hive {
pre_sql = "select * from ods.demo_tbl where dt='2023-03-09'"
result_table_name = "ods_demo_tbl"
}
}
transform {
}
sink {
doris {
fenodes = "192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030"
user = root
password = "XXX"
database = ods
table = ods_demo_tbl
batch_size = 500000
max_retries = 1
interval = 10000
doris.column_separator = "\t"
}
}
该方案成功实施后,资源占用、计算内存占用有了明显的降低,查询性能、导入性能有了大幅提升:
- 存储成本降低
使用前:Hive 原始表包含 500 个字段,单个分区数据量为 1.5 亿/天,在 HDFS 上占用约 810G 的空间。
使用后:我们通过 SeaTunnel 调起 Spark on YARN 的方式进行数据同步,可以在 40 分钟左右完成数据同步,同步后数据占用 270G 空间,存储资源仅占之前的 1/3。
- 计算内存占用降低,性能提升显著
使用前:上述表在 Hive 上进行 Group By 时,占用 YARN 资源 720 核 1.44T 内存,需要 162 秒才可返回结果;
使用后:
- 通过 Doris 调用 Hive Catalog 进行聚合查询,在设置
set exec_mem_limit=16G情况下用时 58.531 秒,查询耗时较之前减少了近 2/3; - 在同等条件下,在 Doris 中执行相同的的操作可以在 0.828 秒就能返回查询结果,性能增幅巨大。
具体效果如下:
(1)Hive 查询语句,用时 162 秒。
select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
group by product_no;
(2)Doris 上 Hive Catalog 查询语句,用时 58.531 秒。
set exec_mem_limit=16G;
select count(*),product_no FROM hive.ods.demo_tbl where dt='2023-03-09'
group by product_no;
(3)Doris 上本地表查询语句,仅用时0.828秒。
select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
group by product_no;
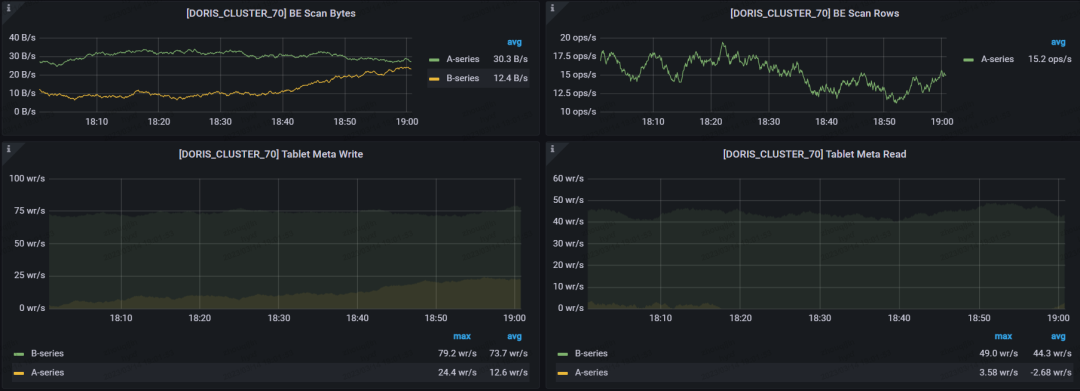
- 导入性能提升
使用前:Hive 原始表包含 40 个字段,单个分区数据量 11 亿/天,在 HDFS 上占用约 806G 的空间
使用后:通过 SeaTunnel 调起 Spark on YARN 方式进行数据同步,可以在 11 分钟左右完成数据同步,即 1 分钟同步约一亿条数据,同步后占用 378G 空间。
可以看出,在数据导入性能的提升的同时,资源也有了较大的节省,主要得益于对以下几个参数进行了调整:
push_write_mbytes_per_sec:BE 磁盘写入限速,300M
push_worker_count_high_priority: 同时执行的 push 任务个数,15
push_worker_count_normal_priority: 同时执行的 push 任务个数,15
02 架构收益
(1)统一数据源出口,查询效率显著提升
风控数据集市采用的是异构存储的方式来存储数据,Apache Doris 的 Multi Catalog 功能成功统一了 ES、Hive、GP 等数据源出口,实现了联邦查询。 同时,Doris 本身具有存储能力,可支持其他数据源中的数据通过外表插入内容的方式快速进行数据同步,真正实现了数据门户。此外,Apache Doris 可支持聚合查询,在向量化引擎的加持下,查询效率得到显著提升。
(2) Hive 任务拆分,提升集群资源利用率
我们将原有的 Hive 跑批任务跟日常的查询统计进行了隔离,以提升集群资源的利用效率。目前 YARN 集群上的任务数量是几千的规模,跑批任务占比约 60%,临时查询分析占比 40%,由于资源限制导致日常跑批任务经常会因为资源等待而延误,临时分析也因资源未及时分配而导致任务无法完成。当部署了 Doris 1.2 之后,对资源进行了划分,完全摆脱 YARN 集群的资源限制,跑批与日常的查询统计均有了明显的改善,基本可以在秒级得到分析结果,同时也减轻了数据分析师的工作压力,提升了用户对平台的满意度。
(3)提升了数据接口的稳定性,数据写入性能大幅提升
之前数据接口是基于 ES 集群的,当进行大批量离线数据推送时会导致 ES 集群的 GC 抖动,影响了接口稳定性,经过调整之后,我们将接口服务的数据集存储在 Doris 上,Doris 节点并未出现抖动,实现数据快速写入,成功提升了接口的稳定性,同时 Doris 查询在数据写入时影响较小,数据写入性能较之前也有了非常大的提升,千万级别的数据可在十分钟内推送成功。
(4)Doris 生态丰富,迁移方便成本较低。
Spark-Doris-Connector 在过渡期为我们减轻了不少的压力,当数据在 Hive 与 Doris 共存时,部分 Doris 分析结果通过 Spark 回写到 Hive 非常方便,当 Spark 调用 Doris 时只需要进行简单改造就能完成原有脚本的复用,迁移方便、成本较低。
(5)支持横向热部署,集群扩容、运维简单。
Apache Doris 支持横向热部署,集群扩容方便,节点重启可以在在秒级实现,可实现无缝对接,减少了该过程对业务的影响; 在架构 1.0 中,当 Hive 集群与 GP 集群需要扩容更新时,配置修改后一般需要较长时间集群才可恢复,用户感知比较明显。而 Doris 很好的解决了这个问题,实现用户无感知扩容,也降低了集群运维的投入。
未来与展望
当前在架构 2.0 中的 Doris 集群在大数据平台中的角色更倾向于查询优化,大部分数据还集中维护在 Hive 集群上,未来我们计划在升级架构 3.0 的时候,完成以下改造:
- 实时全量数据接入:利用 Flink 将所有的实时数据直接接入 Doris,不再经过 ES 存储;
- 数据集数据完整性:利用 Doris 构建实时数据集市的原始层,利用 FlinkCDC 等同步工具将业务库 MySQL与决策过程中产生的 MongoDB 数据实时同步到 Doris,最大限度将现有数据都接入 Doris 的统一平台,保证数据集数据完整性。
- 离线跑批任务迁移:将现有 Hive&Spark 中大部分跑批任务迁移至 Doris,提升跑批效率;
- 统一查询分析出口:将所有的查询分析统一集中到 Doris,完全统一数据出口,实现统一数据查询网关,使数据的管理更加规范化;
- 强化集群稳定扩容:引入可视化运维管理工具对集群进行维护和管理,使 Doris 集群能够更加稳定支撑业务扩展。
总结与致谢
Apache Doris 1.2 是社区在版本迭代中的重大升级,借助 Multi Catalog 等优异功能能让 Doris 在 Hadoop 相关的大数据体系中快速落地,实现联邦查询;同时可以将日常跑批与统计分析进行解耦,有效提升大数据平台的的查询性能。
作为第一批 Apache Doris1.2 的用户,我们深感荣幸,同时也十分感谢 Doris 团队的全力配合和付出,可以让 Apache Doris 快速落地、上线生产,并为后续的迭代优化提供了可能。
Apache Doris 1.2 值得大力推荐,希望大家都能从中受益,祝愿 Apache Doris 生态越来越繁荣,越来越好!
作者|杭银消金大数据团队 周其进,唐海定, 姚锦权
