
背景
Apache Doris 作为基于 MPP 架构的 OLAP 数据库,数据从磁盘加载到内存后,会在算子间流式传递并计算,在内存中存储计算的中间结果,这种方式减少了频繁的磁盘 I/O 操作,充分利用多机多核的并行计算能力,可在性能上呈现巨大优势。
在面临内存资源消耗巨大的复杂计算和大规模作业时,有效的内存分配 、统计、 管控对于系统的稳定性起着十分关键的作用——更快的内存分配速度将有效提升查询性能,通过对内存的分配、跟踪与限制可以保证不存在内存热点,及时准确地响应内存不足并尽可能规避 OOM 和查询失败,这一系列机制都将显著提高系统稳定性;更精确的内存统计,也是大查询落盘的基础。

问题和思考
- 在内存充足时内存管理通常对用户是无感的,但真实场景中往往面临着各式各样的极端 Case ,这些都将为内存性能和稳定性带来挑战,在过去版本中,用户在使用 Apache Doris 时在内存管理方面遭遇了以下挑战:
- OOM 导致 BE 进程崩溃。内存不足时,用户可以接受执行性能稍慢一些,或是让后到的任务排队,或是让少量任务失败,总之希望有效限制进程的内存使用而不是宕机;
- BE 进程占用内存较高。用户反馈 BE 进程占用了较多内存,但很难找到对应内存消耗大的查询或导入任务,也无法有效限制单个查询的内存使用;
- 用户很难合理的设置每个query的内存大小,所以经常出现内存还很充足,但是query 被cancel了;
- 高并发性能下降严重,也无法快速定位到内存热点;
- 构建 HashTable 的中间数据不支持落盘,两个大表的 Join 由于内存超限无法完成。
针对开发者而言又存在另外一些问题,比如内存数据结构功能重叠且使用混乱,MemTracker 的结构难以理解且手动统计易出错等。
针对以上问题,我们经历了过去多个版本的迭代与优化。从 Apache Doris 1.1.0 版本开始,我们逐渐统一内存数据结构、重构 MemTracker、开始支持查询内存软限,并引入进程内存超限后的 GC 机制,同时优化了高并发的查询性能等。在 Apache Doris 1.2.4 版本中,Apache Doris 内存管理机制已趋于完善,在 Benchmark、压力测试和真实用户业务场景的反馈中,基本消除了内存热点以及 OOM 导致 BE 宕机的问题,同时可定位内存 Top 的查询、支持查询内存灵活限制。而在最新的 Doris 2.0 alpha 版本中,我们实现了查询的异常安全,并将逐步配合 Pipeline 执行引擎和中间数据落盘 , 让用户不再受内存不足困扰。
在此我们将系统介绍 Apache Doris 在内存管理部分的实现与优化。
内存管理优化与实现
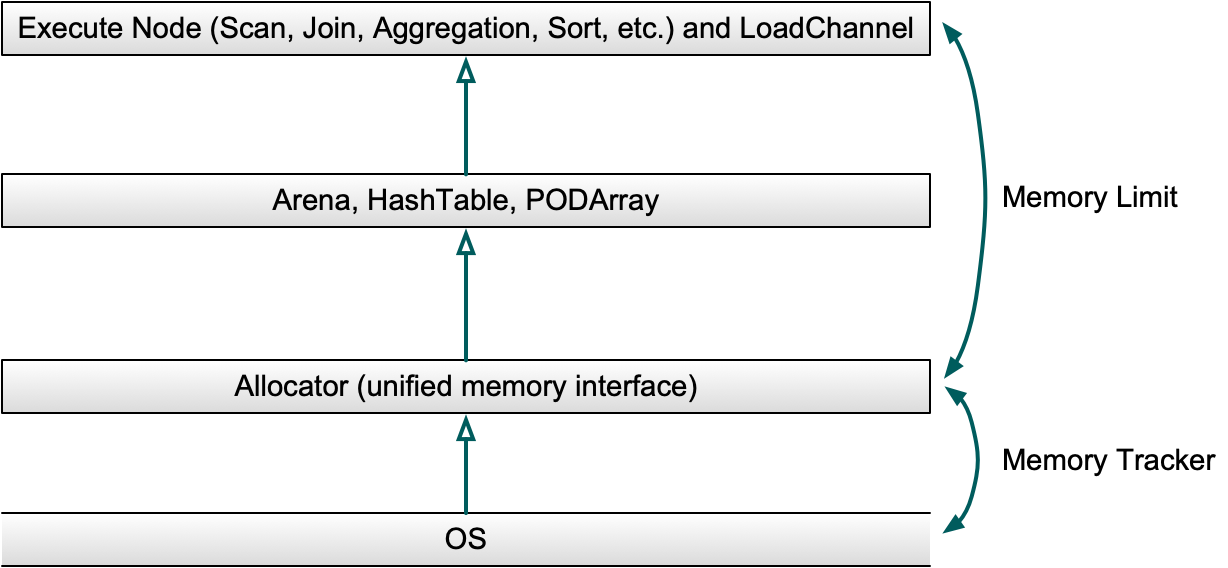
Allocator 作为系统中大块内存申请的统一的入口从系统申请内存,并在申请过程中使用 MemTracker 跟踪内存申请和释放的大小,执行算子所需批量申请的大内存将交由不同的数据结构管理,并在合适的时机干预限制内存分配的过程,确保内存申请的高效可控。
01 内存分配
早期 Apache Doris 内存分配的核心理念是尽可能接管系统内存自己管理,使用通用的全局缓存满足大内存申请的性能要求,并在 LRU Cache 中缓存 Data Page、Index Page、RowSet Segment、Segment Index 等数据。
随着 Doris 使用 Jemalloc 替换 TCMalloc,Jemalloc 的并发性能已足够优秀,所以不在 Doris 内部继续全面接管系统内存,转而针对内存热点位置的特点,使用多种内存数据结构并接入统一的系统内存接口,实现内存统一管理和局部的内存复用。
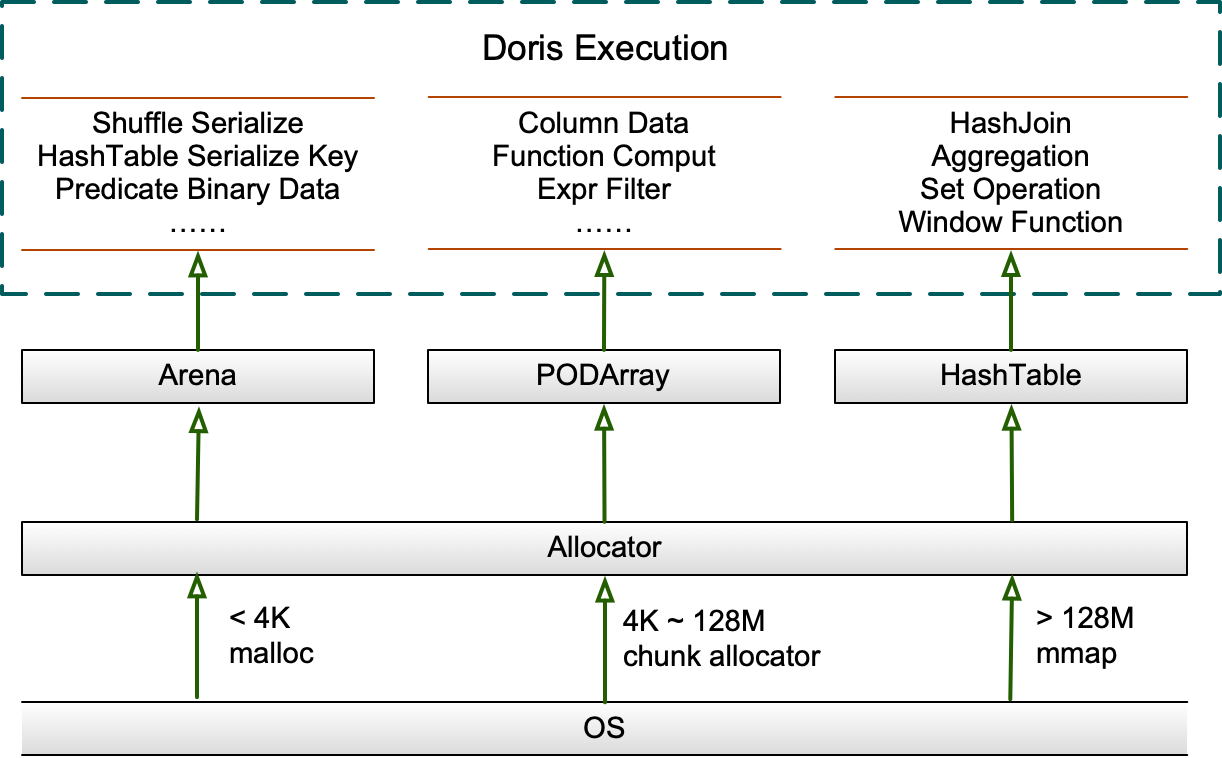
02 内存数据结构
查询执行过程中大块内存的分配主要使用 Arena、HashTable、PODArray 这三个数据结构管理。
- Arena
Arena 是一个内存池,维护一个内存块列表,并从中分配内存以响应 alloc 请求,从而减少从系统申请内存的次数以提升性能,内存块被称为 Chunk,在内存池的整个生命周期内存在,在析构时统一释放,这通常和查询生命周期相同,并支持内存对齐,主要用于保存 Shuffle 过程中序列化/反序列化数据、HashTable 中序列化 Key 等。
Chunk 初始 4096 字节,内部使用游标记录分配过的内存位置,如果当前 Chunk 剩余大小无法满足当前内存申请,则申请一个新的 Chunk 添加到列表中,为减少从系统申请内存的次数,在当前 Chunk 小于 128M 时,每次新申请的 Chunk 大小加倍,在当前 Chunk 大于 128M 时,新申请的 Chunk 大小在满足本次内存申请的前提下至多额外分配 128M ,避免浪费过多内存,默认之前的 Chunk 不会再参与后续 alloc。
- HashTable
Doris 中的 HashTable 主要在 Hash Join、聚合、集合运算、窗口函数中应用,主要使用的 PartitionedHashTable 最多包含 16 个子 HashTable,支持两个 HashTable 的并行化合并,每个子 Hash Join 独立扩容,预期可减少总内存的使用,扩容期间的延迟也将被分摊。
在 HashTable 小于 8M 时将以 4 的倍数扩容,在 HashTable 大于 8M 时将以 2 的倍数扩容,在 HashTable 小于 2G 时扩容因子为 50%,即在 HashTable 被填充到 50% 时触发扩容,在 HashTable 大于 2G 后扩容因子被调整为 75%,为了避免浪费过多内存,在构建 HashTable 前通常会依据数据量预扩容。此外 Doris 为不同场景设计了不同的 HashTable,比如聚合场景使用 PHmap 优化并发性能。
- PODArray
PODArray 是一个 POD 类型的动态数组,与 std::vector 的区别在于不会初始化元素,支持部分 std::vector 的接口,同样支持内存对齐并以 2 的倍数扩容,PODArray 析构时不会调用每个元素的析构函数,而是直接释放掉整块内存,主要用于保存 String 等 Column 中的数据,此外在函数计算和表达式过滤中也被大量使用。
03 统一的内存接口
Allocator 作为 Arena、PODArray、HashTable 的统一内存接口,对大于 64M 的内存使用 MMAP 申请,并通过预取加速性能,对小于 4K 的内存直接 malloc/free 从系统申请,对大于 4K 小于 64M 的内存,使用一个通用的缓存 ChunkAllocator 加速,在 Benchmark 测试中这可带来 10% 的性能提升,ChunkAllocator 会优先从当前 Core 的 FreeList 中无锁的获取一个指定大小的 Chunk,若不存在则有锁的从其他 Core 的 FreeList 中获取,若仍不存在则从系统申请指定内存大小封装为 Chunk 后返回。
Allocator 使用通用内存分配器申请内存,在 Jemalloc 和 TCMalloc 的选择上,Doris 之前在高并发测试时 TCMalloc 中 CentralFreeList 的 Spin Lock 能占到查询总耗时的 40%,虽然关闭aggressive memory decommit能有效提升性能,但这会浪费非常多的内存,为此不得不单独用一个线程定期回收 TCMalloc 的缓存。Jemalloc 在高并发下性能优于 TCMalloc 且成熟稳定,在 Doris 1.2.2 版本中我们切换为 Jemalloc,调优后在大多数场景下性能和 TCMalloc 持平,并使用更少的内存,高并发场景的性能也有明显提升。
04 内存复用
Doris 在执行层做了大量内存复用,可见的内存热点基本都被屏蔽。比如对数据块 Block 的复用贯穿 Query 执行的始终;比如 Shuffle 的 Sender 端始终保持一个 Block 接收数据,一个 Block 在 RPC 传输中,两个 Block 交替使用;还有存储层在读一个 Tablet 时复用谓词列循环读数、过滤、拷贝到上层 Block、Clear;导入 Aggregate Key 表时缓存数据的 MemTable 到达一定大小预聚合收缩后继续写入,等等。
此外 Doris 会在数据 Scan 开始前依据 Scanner 个数和线程数预分配一批 Free Block,每次调度 Scanner 时会从中获取一个 Block 并传递到存储层读取数据,读取完成后会将 Block 放到生产者队列中,供上层算子消费并进行后续计算,上层算子将数据拷走后会将 Block 重新放回 Free Block 中,用于下次 Scanner 调度,从而实现内存复用,数据 Scan 完成后 Free Block 会在之前预分配的线程统一释放,避免内存申请和释放不在同一个线程而导致的额外开销,Free Block 的个数一定程度上还控制着数据 Scan 的并发。
内存跟踪
Doris 使用 MemTracker 跟踪内存的申请和释放来实时分析进程和查询的内存热点位置,MemTracker 记录着每一个查询、导入、Compaction 等任务以及Cache、TabletMeta等全局对象的内存大小,支持手动统计或 MemHook 自动跟踪,支持在 Web 页面查看实时的 Doris BE 内存统计。
01 MemTracker 结构
过去 Doris MemTracker 是具有层次关系的树状结构,自上而下包含 process、query pool、query、fragment instance、exec node、exprs/hash table/etc.等多层,上一层 MemTracker是下一层的 Parent,开发者使用时需理清它们之间的父子关系,然后手动计算内存申请和释放的大小并消费 MemTracker,此时会同时消费这个 MemTracker 的所有 Parent。这依赖开发者时刻关注内存使用,后续迭代过程中若 MemTracker 统计错误将产生连锁反应,对 Child MemTracker 的统计误差会不断累积到他的 Parent MemTracker 中,导致整体结果不可信。
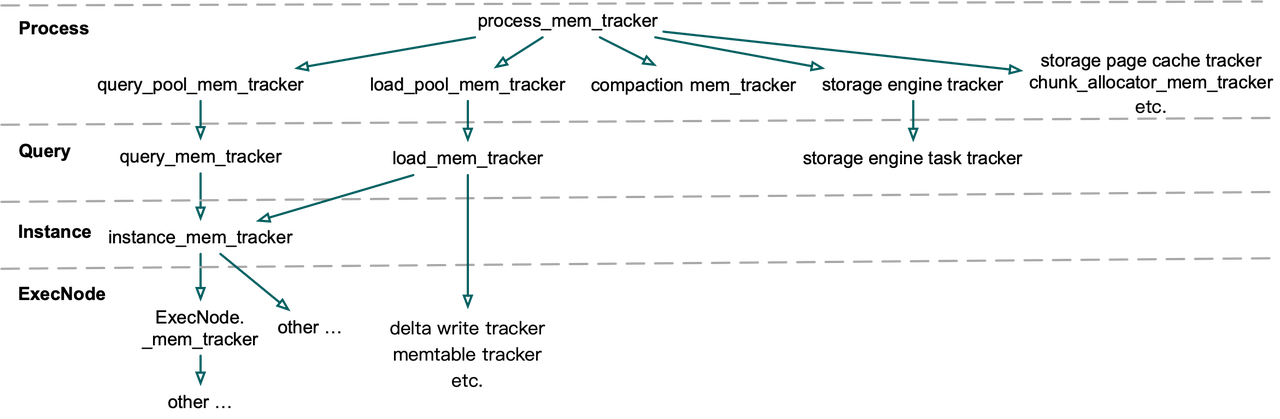
在 Doris 1.2.0 中引入了新的 MemTracker 结构,去掉了 Fragment、Instance 等不必要的层级,根据使用方式分为两类,第一类 Memtracker Limiter,在每个查询、导入、Compaction 等任务和全局 Cache、TabletMeta 唯一,用于观测和控制内存使用;第二类 MemTracker,主要用于跟踪查询执行过程中的内存热点,如 Join/Aggregation/Sort/窗口函数中的 HashTable、序列化的中间数据等,来分析查询中不同算子的内存使用情况,以及用于导入数据下刷的内存控制。后文没单独指明的地方,统称二者为 MemTracker。
二者之间的父子关系只用于快照的打印,使用Lable名称关联,相当于一层软链接,不再依赖父子关系同时消费,生命周期互不影响,减少开发者理解和使用的成本。所有 MemTracker 存放在一组 Map 中,并提供打印所有 MemTracker Type 的快照、打印 Query/Load/Compaction 等 Task 的快照、获取当前使用内存最多的一组 Query/Load、获取当前过量使用内存最多的一组 Query/Load 等方法。
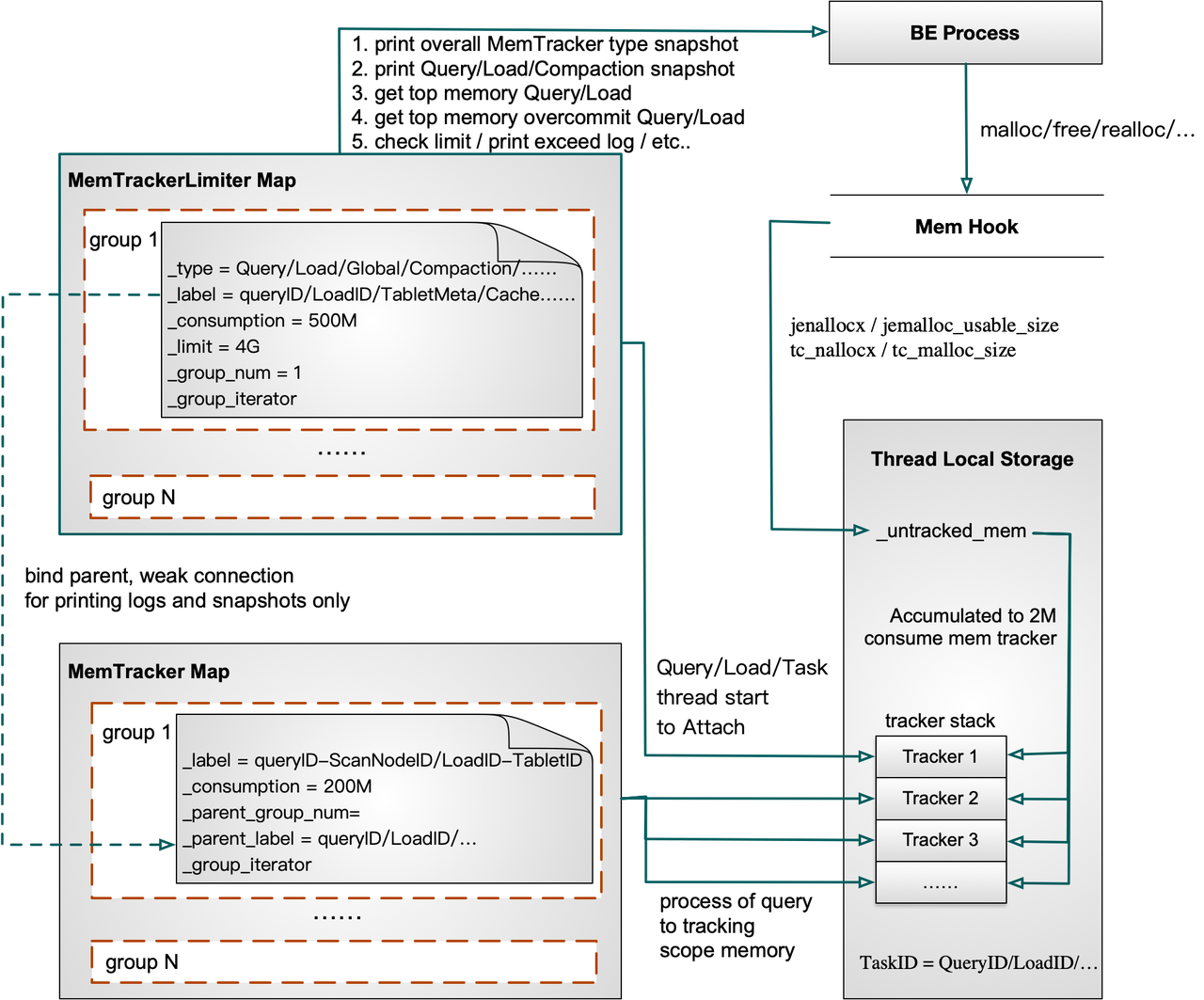
02 MemTracker 统计方式
为统计某一段执行过程的内存,将一个 MemTracker 添加到当前线程 Thread Local 的一个栈中,使用 MemHook 重载 Jemalloc 或 TCMalloc 的 malloc/free/realloc 等方法,获取本次申请或释放内存的实际大小并记录在当前线程的 Thread Local 中,在当前线程内存使用量累计到一定值时消费栈中的所有 MemTracker,这段执行过程结束时会将这个 MemTracker 从栈中弹出,栈底通常是整个查询或导入唯一的 Memtracker,记录整个查询执行过程的内存。
下面以一个简化的查询执行过程为例:
- Doris BE 启动后所有线程的内存将默认记录在 Process MemTracker 中。
- Query 提交后,将 Query MemTracker 添加到 Fragment 执行线程的 Thread Local Storage(TLS) Stack 中。
- ScanNode 被调度后,将 ScanNode MemTracker 继续添加到 Fragment 执行线程的 TLS Stack 中,此时线程申请和释放的内存会同时记录到 Query MemTracker 和 ScanNode MemTracker。
- Scanner 被调度后,将 Query MemTracker 和 Scanner MemTracker 同时添加到 Scanner 线程的 TLS Stack 中。
- Scanner 结束后,将 Scanner 线程 TLS Stack 中的 MemTracker 全部移除,随后 ScanNode 调度结束,将ScanNode MemTracker 从 Fragment 执行线程中移除。随后 AggregationNode 被调度时同样将 MemTracker 添加到 Fragment 执行线程中,并在调度结束后将自己的 MemTracker 从 Fragment 执行线程移除。
- 后续 Query 结束后,将 Query MemTracker 从 Fragment 执行线程 TLS Stack 中移除,此时 Stack 应为空,在 QueryProfile 中即可看到 Query 整体、ScanNode、AggregationNode 等执行期间内存的峰值。
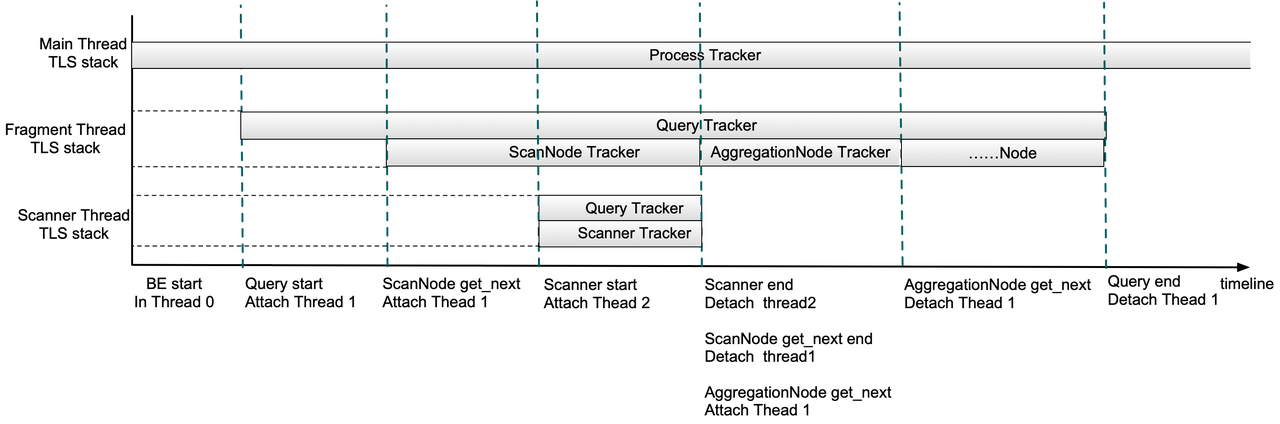
可见为跟踪一个查询的内存使用,在查询所有线程启动时将 Query MemTracker 绑定到线程 Thread Local,在算子执行的代码区间内,将算子 MemTracker 同样绑定到线程 Thread Local,此后这些线程所有的内存申请和释放都将记录在这个查询中,在算子调度结束和查询结束时分别解除绑定,从而统计一个查询生命周期内各个算子和查询整体的内存使用。
期待开发者能将 Doris 执行过程中长时间持有的内存尽可能多地统计到 MemTracker 中,这有助于内存问题的分析,不必担心统计误差,这不会影响查询整体统计的准确性,也不必担心影响性能,在 ThreadLocal 中按批消费 MemTracker 对性能的影响微乎其微。
03 MemTracker 使用
通过 Doris BE 的 Web 页面可以看到实时的内存统计结果,将 Doris BE 内存分为了 Query/Load/Compaction/Global 等几部分,并分别展示它们当前使用的内存和历史的峰值内存,具体使用方法和字段含义可参考 Doris 管理手册:
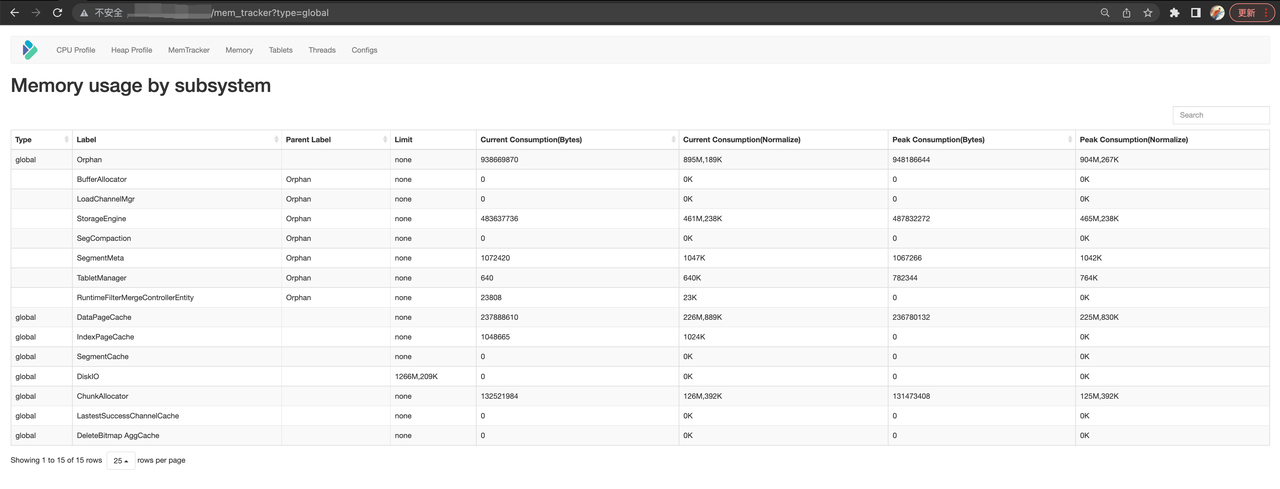
Global 类型的 MemTracker 中,包括全局的 Cache、TabletMeta 等。
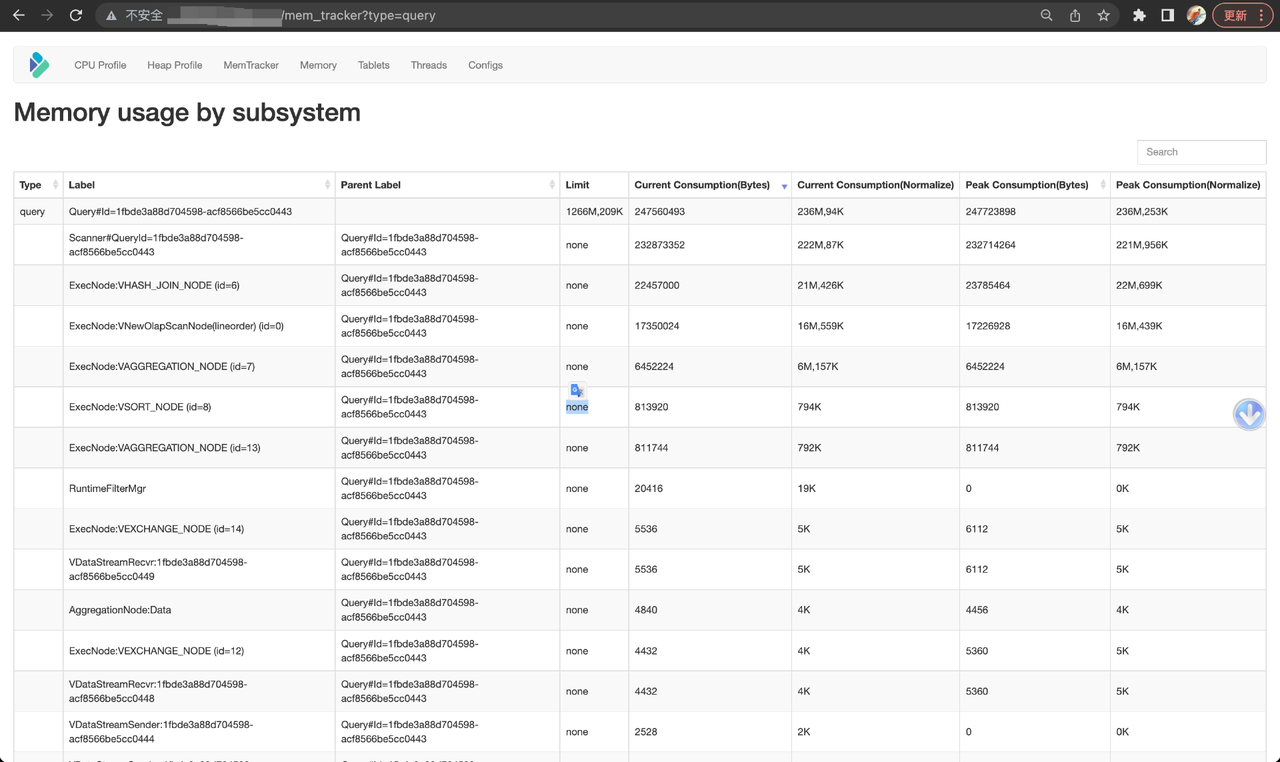
Query 类型的 MemTracker 中,可以看到 Query 和其算子当前使用的内存和峰值内存,通过 Label 将他们关联,历史查询的内存统计可以查看 FE 审计日志或 BE INFO 日志。
内存限制
内存不足导致 OOM 引起 BE 宕机或查询大量失败一直是用户的痛点,为此在 Doris BE 大多数内存被跟踪后,开始着手改进查询和进程的内存限制,在关键内存分配时检测内存限制来保证内存可控。
01 查询内存限制
每个查询都可以指定内存上限,查询运行过程中内存超过上限会触发 Cancel。从 Doris 1.2 开始查询支持内存超发(overcommit),旨在允许查询设置更灵活的内存限制,内存充足时即使查询内存超过上限也不会被 Cancel,所以通常用户无需关注查询内存使用。内存不足时,任何查询都会在尝试分配新内存时等待一段时间,如果等待过程中内存释放的大小满足需求,查询将继续执行, 否则将抛出异常并终止查询。
Doris 2.0 初步实现了查询的异常安全,这使得任何位置在发现内存不足时随时可抛出异常并终止查询,而无需依赖后续执行过程中异步的检查 Cancel 状态,这将使查询终止的速度更快。
02 进程内存限制
Doris BE 会定时从系统获取进程的物理内存和系统当前剩余可用内存,并收集所有查询、导入、Compaction 任务 MemTracker 的快照,当 BE 进程内存超限或系统剩余可用内存不足时,Doris 将释放 Cache 和终止部分查询或导入来释放内存,这个过程由一个单独的 GC 线程定时执行。
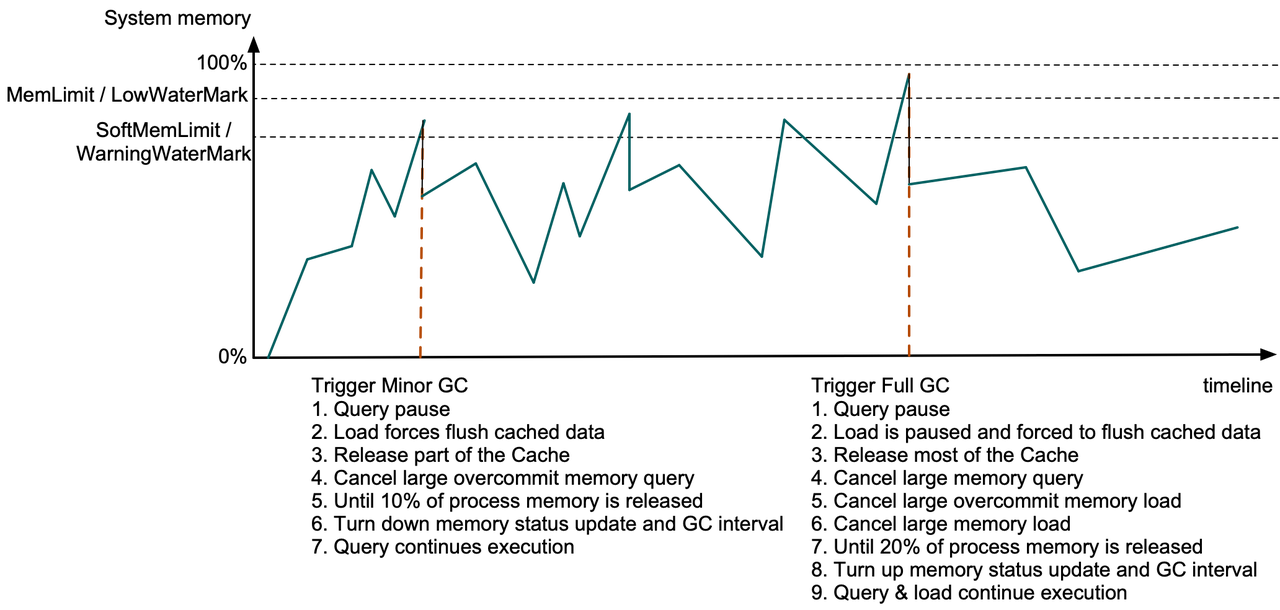
若 Doris BE 进程内存超过 SoftMemLimit(默认系统总内存的 81%)或系统剩余可用内存低于 Warning 水位线(通常不大于 3.2GB)时触发 Minor GC,此时查询会在 Allocator 分配内存时暂停,同时导入强制下刷缓存中的数据,并释放部分 Data Page Cache 以及过期的 Segment Cache 等,若释放的内存不足进程内存的 10%,若启用了查询内存超发,则从内存超发比例大的查询开始 Cancel,直到释放 10% 的进程内存或没有查询可被 Cancel,然后调低系统内存状态获取间隔和 GC 间隔,其他查询在发现剩余内存后将继续执行。
若 BE 进程内存超过 MemLimit(默认系统总内存的 90%)或系统剩余可用内存低于 Low 水位线(通常不大于1.6GB)时触发 Full GC,此时除上述操作外,导入在强制下刷缓存数据时也将暂停,并释放全部 Data Page Cache 和大部分其他 Cache,如果释放的内存不足 20%,将开始按一定策略在所有查询和导入的 MemTracker 列表中查找,依次 Cancel 内存占用大的查询、内存超发比例大的导入、内存占用大的导入,直到释放 20% 的进程内存后,调高系统内存状态获取间隔和 GC 间隔,其他查询和导入也将继续执行,GC 的耗时通常在几百 us 到几十 ms 之间。
总结规划
通过上述一系列的优化,高并发性能和稳定性有明显改善,OOM 导致 BE 宕机的次数也明显降低,即使发生 OOM 通常也可依据日志定位内存位置,并针对性调优,从而让集群恢复稳定,对查询和导入的内存限制也更加灵活,在内存充足时让用户无需感知内存使用。
后续我们将让 Apache Doris 从“能有效限制内存”转为“内存超限时能完成计算”,尽可能减少查询因内存不足被 Cancel,主要工作将聚焦在异常安全、资源组内存隔离、中间数据落盘上:
- 查询和导入支持异常安全,从而可以随时随地的抛出内存分配失败的 Exception,外部捕获后触发异常处理或释放内存,而不是在内存超限后单纯依赖异步 Cancel。
- Pipeline 调度中将支持资源组内存隔离,用户可以划分资源组并指定优先级,从而更灵活的管理不同类型任务使用的内存,资源组内部和资源组之间同样支持内存的“硬限”和“软限”,并在内存不足时支持排队机制。
- Doris 将实现统一的落盘机制,支持 Sort,Hash Join,Agg 等算子的落盘,在内存紧张时将中间数据临时写入磁盘并释放内存,从而在有限的内存空间下,对数据分批处理,支持超大数据量的计算,在避免 Cancel 让查询能跑出来的前提下尽可能保证性能。
以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0 Alpha 版本的专项支持群,请大家戳此填写申请,欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。


