
导读:随着川航大规模数据导入需求增长,数据响应频繁出现卡顿,原 Hadoop + Apache Doris 的数据架构存在着涉及组件多、并发性不足、数据导入受限的痛点。经过综合选型对比,川航选择引入 SelectDB 建设湖仓一体大数据分析引擎,取得了数据导入效率提升 3-6 倍,查询分析性能提升 10-18 倍、实时性提升至 5 秒内等收益。
本文转录自吴乐(四川航空 信息技术部 大数据架构师)在 Doris Summit Asia 2024 上的演讲,经编辑整理。
业务背景
四川航空股份有限公司(以下简称:川航),自开航至今持续安全飞行 36 年,现运营全空客机队超过 200 架飞机,年运送旅客量超过 3000 万,航线覆盖亚洲、欧洲、北美洲、大洋洲和非洲,品牌价值超过 900 亿。
航空公司的业务具有业务系统繁多、数据交互复杂、实时性要求高三大特点。
- 业务系统繁多:航空公司业务覆盖航班调度、票务销售、旅客服务、机组管理、机务维修、财务结算等多个领域,运营跨国航班还需满足不同国家法规与合规要求,这就使得涉及的基础架构与数据库种类繁多。
- 数据交互复杂:多业务系统间数据交互具有复杂性,航空公司与机场、民航局、中航信等多方存在航班运行、航班动态、旅客信息、地面信息保障等大量数据共享。在与中航信数据交互时,无论是川航自有渠道还是第三方平台购票,订单均先经中航信系统,再以报文等形式传至航司,交互流程颇为复杂。
- 实时性要求高:需要实时更新旅客登机、行李、座位安排数据、保障旅客乘机体验。同时,需要实时更新航班起降时间与状态,避免冲突,保障飞行安全。
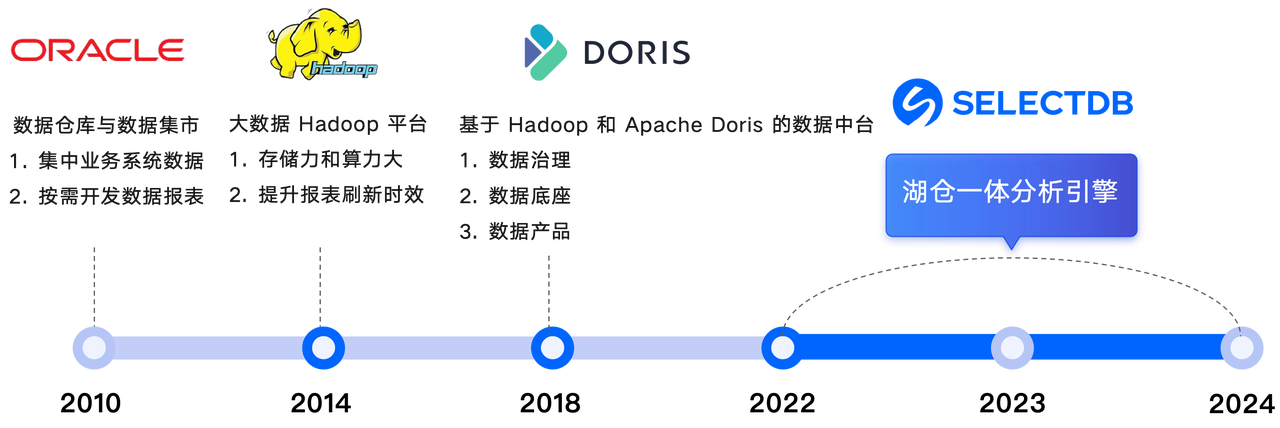
2010 年,川航使用 Oracle 建设简单数仓用于报表查询。随着数据量增长,2014 年,川航转用 Hadoop 大数据平台,建立离线数仓以提升报表刷新时效。为满足更高的实时性与查询性能需求,在 2018 年,川航采用 Hadoop + Apache Doris 构建数据中台。然而,随着大规模数据导入需求增长,该架构涉及组件繁多,数据响应频繁出现卡顿。2022 年,我们选择 Apache Doris 作为数据分析的主要入口,并最终选择 Apache Doris 企业版 SelectDB 建设湖仓一体大数据分析引擎,统一 OLAP 技术栈与数据服务。
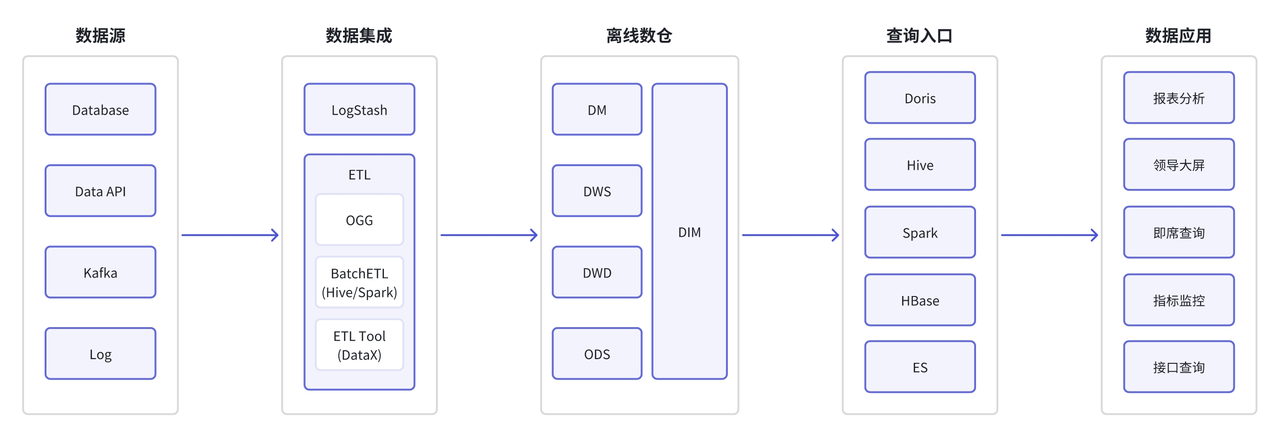
川航早期数据架构分为数据源、数据集成、离线数仓、查询入口与数据应用五大部分:
- 数据源:数据源包含各个业务系统数据库、接口 API、以及中航信通过消息队列 Kafka、飞机 Acars 日志所共享的报文数据;
- 数据集成:采用 LogStash 进行日志集成,采用 OGG 与 DataX 实现离线数据同步,采用 Hive 进行批处理;
- 离线数仓:采用 Hadoop 构建传统离线数仓,用于统一存储多源异构数据,建立统一离线数据仓库,并用于历史数据归档;
- 查询入口:包含 Apache Doris、Hive、Spark、HBase、Elasticsearch 查询引擎,分别应用于实时数据分析、离线数据分析、数据湖分析、高并发查询、日志数据分析查询场景;
- 数据应用:包含报表大屏与接口服务,支撑领导管理驾驶舱,日常业务分析运营,重点经营指标监控等应用。
该架构存在以下痛点:
- 涉及组件多:由于航空公司业务系统繁多,为满足多类业务需求,该架构湖仓分离,涉及查询组件较多,使得架构复杂,导致运维困难;
- 并发性不足:在早期架构下,大部分数据分析处理保留在以 Hadoop 为主的离线数仓中,导致系统整体并发性较低,无法满足川航日常需求;
- 数据导入受限:该架构数据集成采用了以传统 Hadoop 工具为主的离线模式,数据导入方式传统单一,存在大规模数据导入瓶颈,数据导入实效性受限。
基于 SelectDB 构建湖仓一体大数据分析引擎
为解决以上痛点,川航决定升级数据架构以满足航班、票务、旅客、机组、机务、财务等多个领域+多样化数据“采存管用”需求。经过综合评估,川航最终选择 Apache Doris 企业版 SelectDB 建设湖仓一体大数据分析引擎。SelectDB 湖仓一体特性通过多源数据目录(Multi-Catalog)功能,支持了包括 Apache Hive、Apache Iceberg、Apache Hudi、Apache Paimon、LakeSoul、MySQL、Oracle、SQL Server 等主流数据湖、数据库的连接访问,并可以通过 Apache Ranger 等实现统一权限管理。
SelectDB 凭借湖仓一体特性、丰富导入方式、卓越性能表现及广泛生态支持,有效解决了川航的多项痛点,全面满足其业务需求:
- 湖仓一体: SelectDB 湖仓一体特性帮助川航简化多组件与多数据源对接,加速数据导入和集成,统一查询网关和入口,优化数据湖仓查询效率。
- 导入方式丰富: SelectDB 支持 HDFS、Kafka、Spark、Flink、Routine Load、Broker Load 以及 Stream Load 等多种数据导入方式 ,满足川航不同场景需求,且导入性能优异;
- 高并发性能卓越: 面对大数据量与高并发时,SelectDB 能够展现出出色的性能,有效替换 Hive、Spark 提供高效数据查询服务;
- Join 能力出色: SelectDB 大表 Join 处理表现出色,支持 Broadcast Join、Shuffle Join、Hash Join 等多种分布式 Join 方式,满足了川航广泛存在的跨业务大表数据关联分析需求;
- 丰富数据生态集成: SelectDB 兼容 Spark、Flink、DataX、SeaTunnel 等计算框架,官方文档提供代码示例,易于工程师使用。
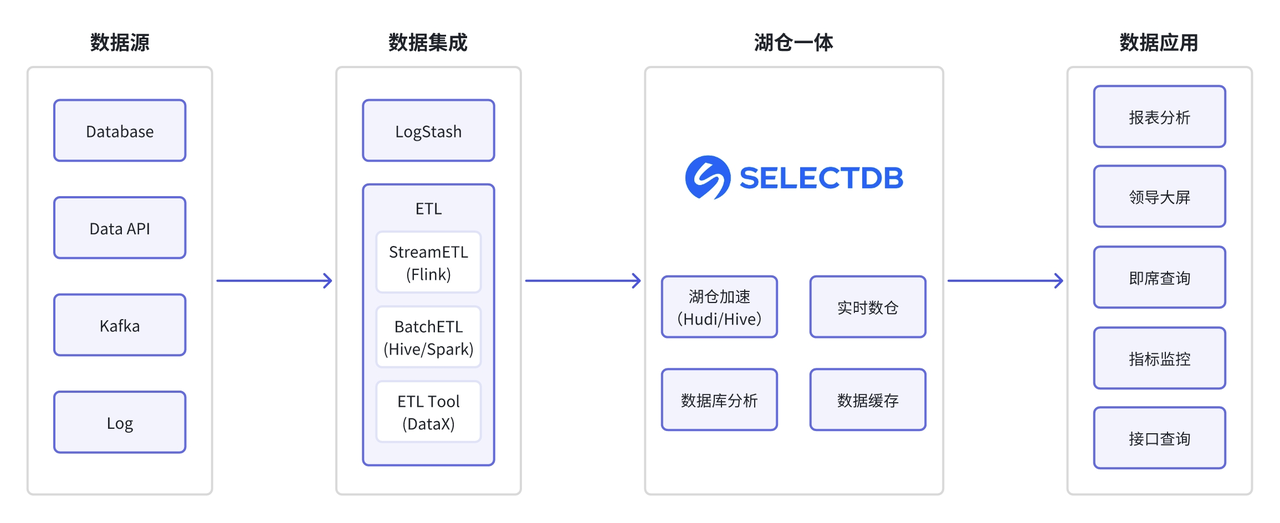
基于 SelectDB 的新架构在数据集成和分析引擎上完成升级:
- 数据集成:川航使用 Flink 替换 OGG 进行实时数据集成,并通过多源数据目录(Multi-Catalog)补充 DataX 做离线数据集成,同时利用 Routine Load、Broker Load、Stream Load 等功能丰富了数据集成方式;
- 分析引擎:川航采用 SelectDB 替换 Spark、HBase、ES 等组件,实现统一查询入口和门户,从湖仓分离升级为湖仓一体架构。
多源数据联邦分析

在基于 SelectDB 的湖仓一体架构中,业务库中的航班调度、旅客服务数据直接通过 FlinkCDC 实时同步入仓。消息报文等数据则通过 Routine Load 从 Kafka 消费入仓。数据湖 Hive 存储 Acars 日志数据,通过 Hive Catalog 与 SelectDB 快速内表关联,加速查询。对于不常用的数据库,川航直接通过外表查询接入 SelectDB,实现高效分析查询。
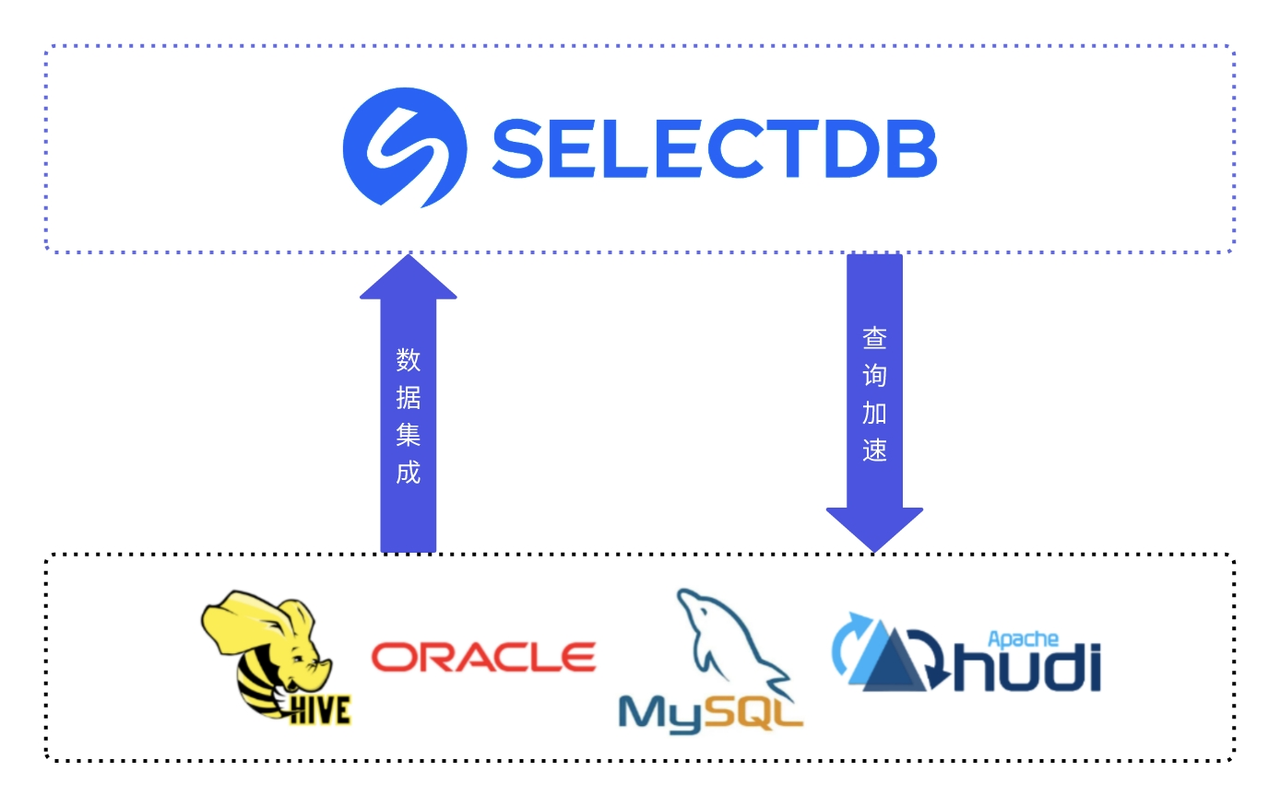
SelectDB 统一了联邦数据湖分析场景的查询入口,使得川航能够借助 JDBC Catalog 直连 MySQL、Oracle 等数据源,实现跨数据源联邦分析,同时也可作为 JDBC 类数据集成的有效途径。此外,川航通过 Hive Catalog 可直接访问 Acars 飞机日志,并与内部表关联,加速分析进程。
## 川航通过 Hive Catalog 直接访问 Acars 飞机日志
CREATA CATALOG HIVE
PROPERTIES(
'type' = 'hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
);
SELECT * FROM HIVE.DB.TABLE a JOIN INTERNAL.DB.TABLE b
ON a.id = b.id
部分数据导入也可直接使用 Hive 通过 Insert 方式插入至 SelectDB 内部表。
INSERT INTO INTERNAL.DB.TABLE SELECT * FROM HIVE.DB.TABLE WHERE DATE = "2024-11-21";
部分数据湖分析数据可以直接对业务数据库做数据写回,并进行数据分析。
INSERT INTO JDBC.DB.TABLE1 SELECT * FROM HIVE.DB.TABLE
WHERE DATE = "2024-11-21";
川航基于 SelectDB 湖仓一体架构,有效解决了复杂业务系统中数据源众多、交付复杂、导入受限等问题,显著提升了异构数据源间的联邦与关联分析效率,并实现了简单高效的数据交换与共享。
多维度快速检索分析
SelectDB 倒排索引特性能够加速字符串数据全文检索,并支持自定义分词,能够很好地支撑多维度快速检索分析,从海量数据中快速筛选符合条件的行。
川航充分利用 SelectDB 倒排索引特性,结合乘客乘机体验评价数据,实现了词云展示。通过分析乘客反馈中的关键词,川航能够直观地展示出乘客最关心的服务内容与体验,从而为后续的服务改进提供数据支持。

通过对比测试,川航发现使用倒排索引后,查询性能相比传统的 LIKE 或全文检索匹配,提升了约 4 倍。这一显著提升减少了数据检索时间成本,帮助川航更快地响应市场变化和客户需求。
未来,SelectDB 的倒排索引特性将应用于川航更多场景,例如结合川航情感分析模型,实现更深入的数据分析。
提升数据实时性
数据建模
为满足川航多样化场景需求,确保数据处理灵活、高效、实时,选用恰当的表模型至关重要。SelectDB 支持包含聚合模型、主键模型以及明细模型在内的多种数据表模型。川航基于 SelectDB 的数据建模规则如下。
- Aggregate Key 聚合模型:应用至数仓集市层,进行报表统计、指标聚合工作。
## 职级人数聚合示例
CREATE TABLE selectdb_agg_tab(
flight_id varchar(30),
date varchar(30),
ac_cnt BIGINT SUM DEFAULT '0'
) AGGREGATE KEY(flight_id, date)
DISTRIBUTED BY HASH(flight_id) BUCKETS 10

Unique Key 主键模型:应用于 ODS 层,进行唯一性数据更新,例如对航班状态、客票状态更新。
## 航班编号更新示例 CREATE TABLE selectdb_uni_tab( flight_id varchar(30), date varchar(30), status varchar(30), ) UNIQUE KEY(flight_id) DISTRIBUTED BY HASH(flight_id) BUCKETS 10
Duplicate Key 明细模型:应用于对明细数据与变更记录进行分析的场景。
CREATE TABLE selectdb_dup_tab( tkt_id varchar(30), date varchar(30), status varchar(30), ) DUPLICATE KEY(tkt_id) DISTRIBUTED BY HASH(tkt_id) BUCKETS 10
高频数据更新
航空公司小批量实时数据导入更新需求频繁。为此,川航利用 SelectDB Merge-on-Write 更新能力实现小批量实时数据高频导入,并基于主键进行高频数据更新。SelecDB 主键模型专为数据更新设计。支持 Merge-on-Read(MoR)和 Merge-on-Write(MoW)两种存储方式,MoR 模式优化写入性能,MoW 则提供了更好的分析性能。目前,川航数仓 ODS 层数据通过 CDC 实时同步导入,全部采用 Merge on Write 表,基于主键进行 UPSERT 操作,提升性能。
CREATE TABLE ODS_SCALFOC.'ODS_FLIGHT_BASIC_INFO'(
'FLIGHT_ID' decimal(9,0) NULL COMMENT '航班主键',
'FLIGHT_DATE' date NULL COMMENT '航班日期',
'FLIGHT_TYPE' varchar(23) NULL COMMENT '航班类型',
.......
)ENGINE = OLAP
UNIQUE KEY('FLIGHT_ID','FLIGHT_DATE')
COMMENT 'OLAP'
DISTRIBUTED BY HASH('FLIGHT_ID') BUCKETS 10
PROPERTIES(
"replication_allocation" = "tag.location.default:3",
"enable_unique_key_merge on write" = "true"
);
测试发现,在测试数据 500 GB 的情况下,常规查询及复杂关联使用 Merge on Write 相较于 Merge on Read,性能提升近 4 倍。

部分列更新
SelectDB 部分列更新特性允许直接更新表中特定字段值,而非整行数据。在主键模型中,SelectDB 支持直接插入或更新部分列数据,无需读取整行数据,从而显著提升更新效率。以川航的航班报文更新为例,通常报文包含数十条基础信息,以往信息单项变更需要更新全部业务字段,效率比较低。在此场景下,SelectDB 部分列更新的能力至关重要。
## 航班状态变更报文样例片段
{
"Hdr":{
"Ver": "v1.0",
"Event": "StatusChange",
"Subevent": "CC",
"Newval": "CC",
"Oldval": "CI",
"Uptm": "20241104131901310",
"Stamp": "0b672c44-7c58-46d8-a565-e8516eec4568"
},
"Dat":{
"Flight":{
"AirlineCode": "3U",
"FilghtNumber": "9821",
"International": "I",
"Route": "CTU-ALA-BUD",
"FlightDate": "2024-11-04",
"FlightStatus": "CC",
"Suffix": "",
"DepAirport": "CTU",
"ArrAirport": "ALA"
}
}
}
该特性应用后,川航每日接收大量报文输入后,往往仅需对航班基本要素与航班状态字段进行更新,极大提升了效率。若无部分列更新能力,则需使用 Update 语句,更新较慢,严重影响性能。

报文传输后,川航通过内部 Stream Load,并使用 Flink 进行设置(代码如下所示),即可实时仅更新航班基本要素(主键)与状态。实现高效合并更新。
## Flink 设置部分列更新
'sink.properties.partial_columns' = 'true'
## 在 sink.properties.column 中指定要导入的列(必须包含所有 key 列,不然无法更新)
应用收益
川航完成基于 SelectDB 的湖仓一体大数据分析引擎升级后,数据实时性、并发性、导入能力均取得显著提升,获得业务部门的广泛好评,并取得了以下关键收益:
- 跨系统业务整合:在数据湖场景中,SelectDB 整合多数据源,提供统一分析平台,通过直连数据源提升实时性,并支持跨系统数据整合分析,提高数据利用率;
- 数据导入效率提升 3-6 倍:通过 FlinkCDC 替换 Oracle OGG 实现实时数据集成,结合 DataX 完成离线数据集成,并借助 SelectDB 2.1 版本性能优化,使得数据导入效率提升 3-6 倍,ETL 效率提升 5-13 倍;
- 查询分析性能提升 10-18 倍:新架构在性能上实现飞跃,多表 Join 能力提升 5-10 倍,同时,湖仓一体架构也显著优化了 Hive 离线数据分析性能,提升幅度可达 20 倍,使得川航日均查询量提升至 1000 万+ 次,查询秒级响应占比达 96%;
- 实时性提升至 5 秒内:SelectDB 2.1 版本 Group Commint 能力进一步提升了数据高并发低延迟导入性能,优化川航数据集成实时性,使得查询实时性提升至 5 秒内;
未来展望
四川航空应用 SelectDB 构建湖仓一体大数据分析引擎,解决了原架构涉及组件多、并发性不足、数据导入受限的问题,并取得了数据导入效率提升 3-6 倍,查询分析性能提升 10-18 倍、实时性提升至 5 秒内等收益。
未来,四川航空深度探索更多特性在场景应用中的可能性,以进一步降低成本并提升效率:
- 存算分离架构:从存算一体架构升级为存算分离架构,实现弹性扩缩容,在数据湖场景下更灵活地弹性部署,并引入更廉价的存储介质降低成本;
- CCR 主备集群同步优化:目前川航已经搭建部署了 CCR 容灾集群,但仍存在一些瑕疵。未来,川航也将应用 SelectDB 继续探索主备集群自动负载及数据故障自动恢复;
- 统一日志分析:使用 SelectDB 倒排索引特性替换 Elasticsearch 完成日志分析,降低存储与维护成本;
- 完善自动化运维:川航计划引入 Doris Manager 接管生产集群运维。通过内部审计日志进行血缘分析,并完善表热度分析与慢查询自动监控,提升集群运维能力。
加入交流群
如果您对 SelectDB 湖仓一体相关特性感兴趣,欢迎扫描下方二维码加入 SelectDB 产品交流群交流沟通。



