
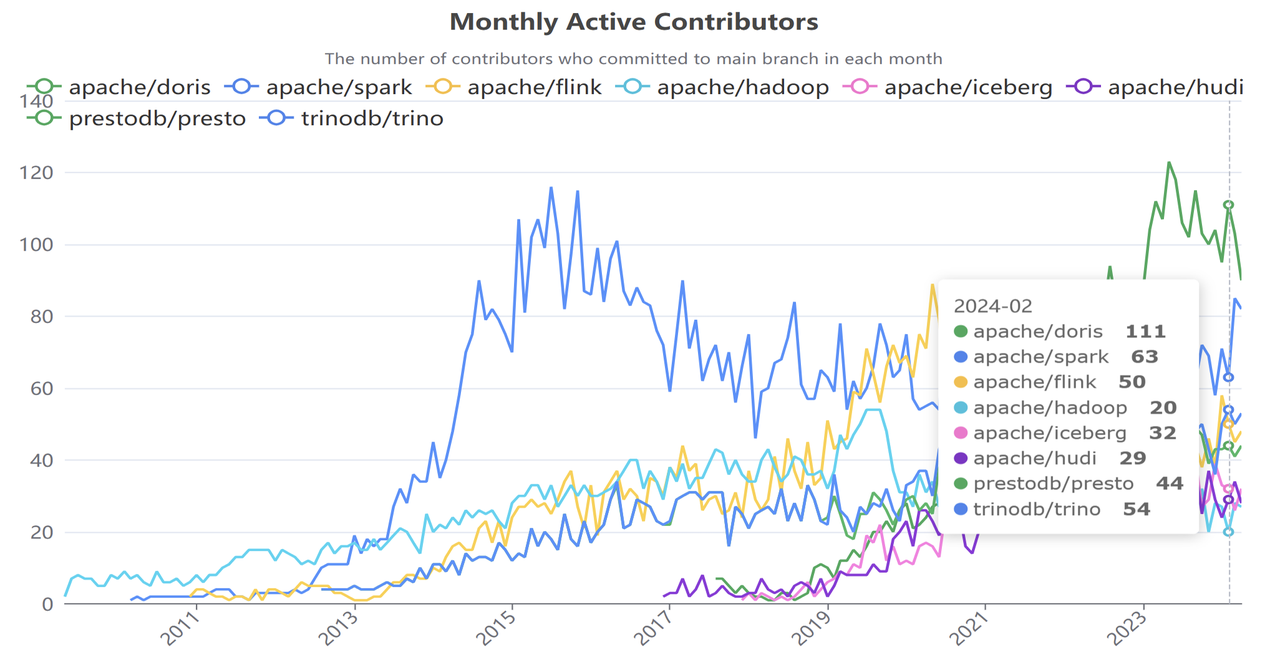
Apache Doris 是一款开源的 MPP 数据库,以其优异的分析性能著称,被各行各业广泛应用在实时数据分析、湖仓融合分析、日志与可观测性分析、湖仓构建等场景。Apache Doris 目前被 5000 多家中大型的企业深度应用在生产系统中,包含互联网、金融、制造、电信、能源、物流、政务等行业。目前项目已在 GitHub 获得超过 13000 Star,汇集 600 多名社区开发者,月度活跃贡献者数量连续数月位居全球大数据开源项目榜首,成为全球大数据领域最活跃的开源项目之一。
SelectDB 是北京飞轮数据科技有限公司基于 Apache Doris 研发的现代化实时数据仓库,提供包括面向私有化部署的 SelectDB Enterprise 和云原生存算分离的 SelectDB Cloud 云数仓服务。SelectDB 兼容 Apache Doris 的所有能力和接口,相比开源自建在安全、稳定、资源弹性等方面有明显优势。本文将对 Doris & SelectDB 适合的分析场景和技术能力进行概述解析。
1 Doris 与 SelectDB 典型分析场景
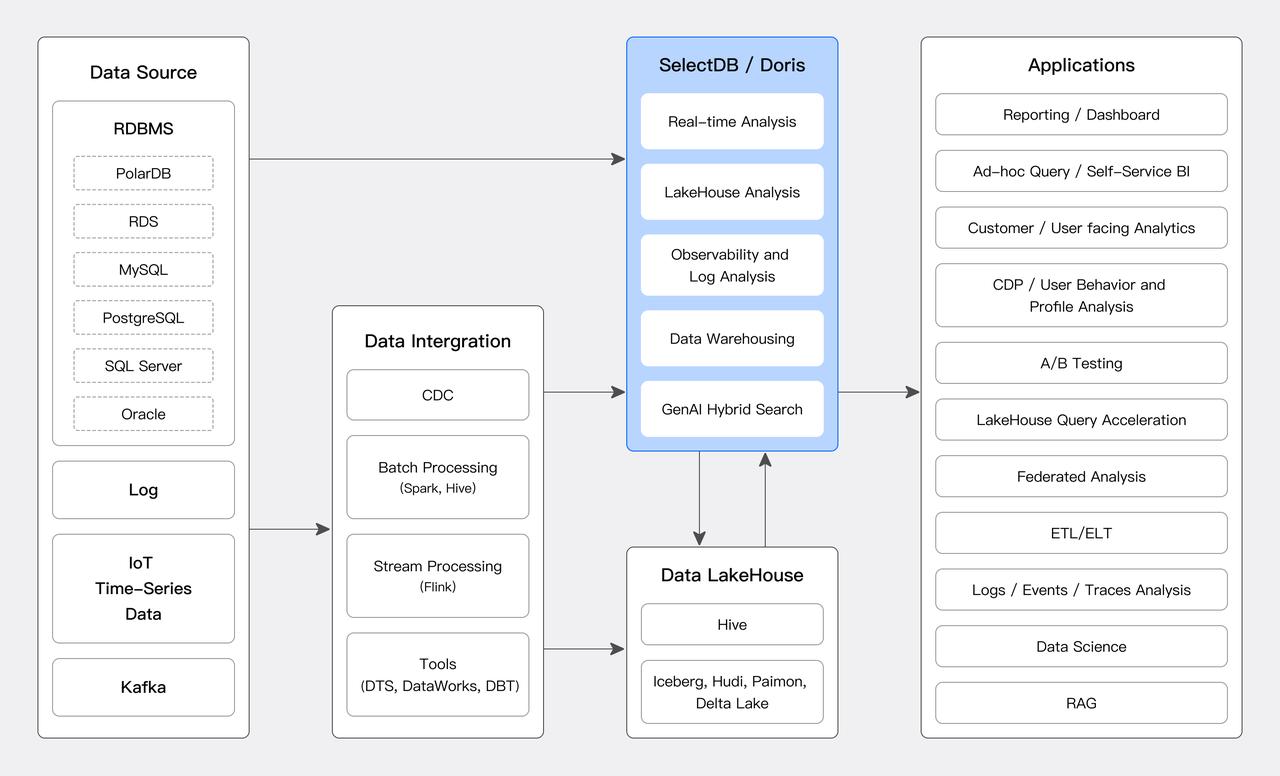
SelectDB 与 Doris 在如下的分析场景中通常是最优选择:
- 实时分析
- 面向内部的实时报表和 Dashboard。
- Ad-Hoc 分析和自助式 BI。
- 面向终端客户 / 用户的高并发分析(Customer / User Facing Analysis):比如电商平台面向数百万广告主 / 店铺的数据分析、面向数十万快递员的分析,这类分析通常需要非常高的并发和较低的延时。
- 用户行为和画像分析(CDP,Customer Data Platform):分析用户参与、留存、转化等行为,A/B Testing,支持人群洞察和人群圈选等画像分析,实现精细化的运营和精准的营销。
- 湖仓融合分析
- 湖仓查询和计算加速:作为查询引擎直接查询 Iceberg, Hudi, Paimon, DeltaLake, Hive 等湖仓中的数据,在不移动数据的情况下,实现查询分析的数倍加速。
- 多源联邦分析:作为统一的查询网关,支持跨多个数据源查询位于数据湖、数据仓库、数据库中的数据,实现联邦查询,简化架构并消除数据孤岛。
- 可观测性和日志分析
- 实现对日志、事件、traces 的高效存储和分析,替换 Elasticsearch, Loki, ClickHouse 等方案,实现数倍的性价比提升。
- 湖仓构建
- 对数据进行 ETL / ELT 实现数据的加工和建模,数据可以统一在 SelectDB & Doris 中存储管理,也可以将加工处理过的数据回写到 Iceberg,Hudi,Paimon,DeltaLake,Hive 等 Data LakeHouse 中,实现湖仓融合构建。
2 Doris 与 SelectDB 技术能力解析
2.1 极速
Doris & SelectDB 的查询分析性能非常优异,在宽表聚合分析和复杂多表关联场景中均表现突出:
- 在宽表聚合场景下,使用 SSB-FLAT benchmark 测试,相同资源下,是 ClickHouse 的 3.4 倍,是 Presto 的 92 倍,是业界标杆产品 Snowflake 的 6 倍。
- 在多表关联场景下,使用 TPC-H benchmark 测试,相同资源下,其性能可达到 Redshift 的 1.5 倍,ClickHouse 的 49 倍,是业界标杆产品 Snowflake 的 2.5 倍,是 Greenplum 和 Presto 的 15 倍。
Doris & SelectDB 如此卓越的性能主要得益于以下技术加持:
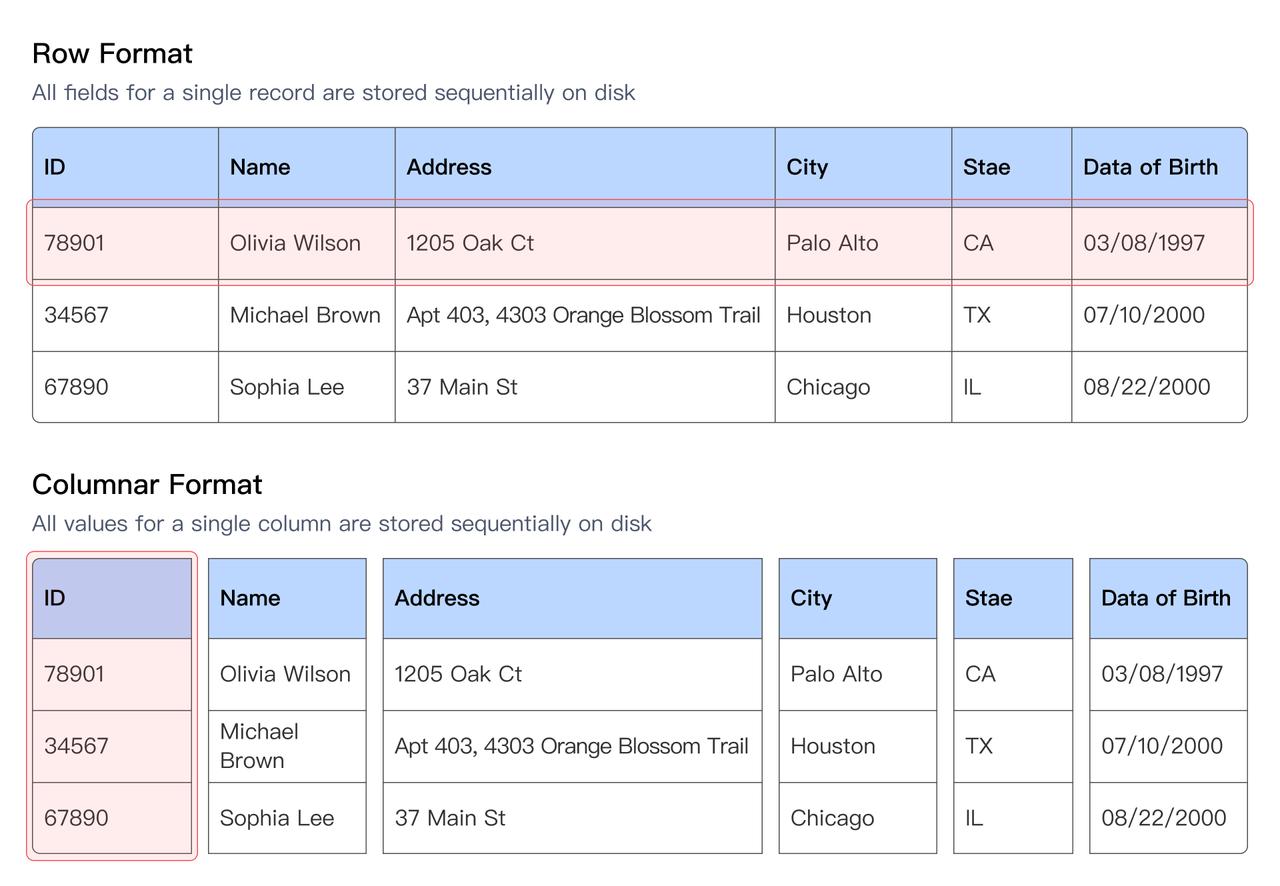
2.1.1 列式存储
Doris & SelectDB 默认使用列式存储组织数据,在数据分析场景下,相比行存储通常有 5-10 倍的性能提升,这是因为:
- 只需要读取 SQL 查询涉及的列,不相关的列无需读取和解压过滤,大大降低了 IO 和 CPU 开销。
- 同一列的数据类型一致,方便进行高效的数据编码和压缩。数值类型采用 RLE 编码,字符串使用字典编码。编码后使用 LZ4 或者 ZSTD 等压缩算法压缩,大幅减少了数据存储空间,也节省了读取 IO。
2.1.2 丰富的索引
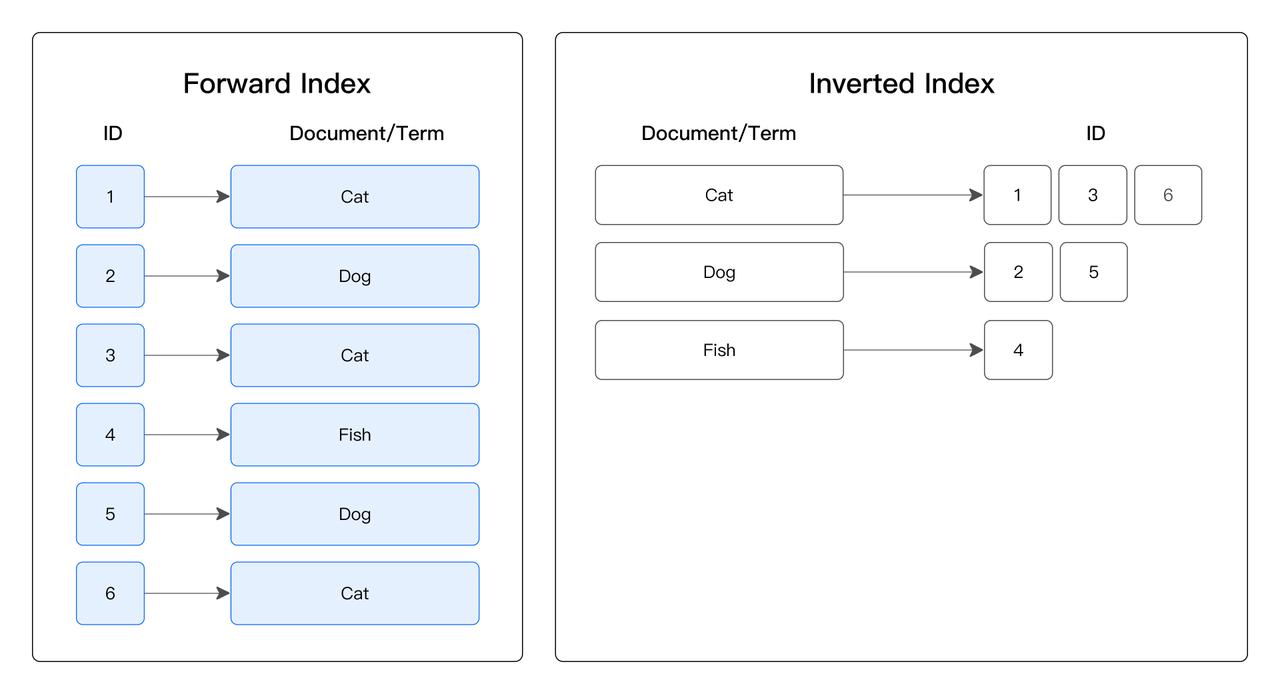
Doris & SelectDB 支持丰富的索引机制,通过索引机制,可以大幅减少对不相关数据的读取和处理,从而能够大幅提升性能。从加速的查询和原理来看,Doris & SelectDB 的索引分为点查索引和跳数索引两大类。
点查索引:常用于加速点查。 其原理是通过索引定位到满足 WHERE 条件的位置,直接读取其所在行。点查索引在满足条件的行数较少时,效果尤为显著。其点查索引包括前缀索引和倒排索引。
前缀索引:按照排序键以有序的方式存储数据,并每隔 1024 行数据创建一个稀疏前缀索引。索引中的 Key 是当前 1024 行中第一行中排序列的值。如果查询涉及已排序列,系统将找到相关 1024 行组的第一行,并从该行开始扫描。
倒排索引:对创建了倒排索引的列,建立每个值到对应行号集合的倒排表。对于等值查询,先从倒排表中查到行号集合,然后直接读取对应行的数据,而无需逐行扫描匹配数据,从而减少 I/O 、加速查询。倒排索引还能加速范围过滤、文本关键词匹配,算法更加复杂但基本原理类似。
跳数索引:常用于加速分析。 原理是通过索引确定不满足 WHERE 条件的数据块,跳过这些不满足条件的数据块,只读取可能满足条件的数据块并再进行一次逐行过滤,最终得到满足条件的行。跳数索引在满足条件的行比较多时效果较好。其跳数索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
ZoneMap 索引:自动维护每一列的统计信息,为每一个数据文件(Segment)和数据块(Page)记录最大值、最小值、是否有 NULL、Sum。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。比如下方 SQL 所示,有一个过滤条件
a<='100101',总共有三个数据块,第一个数据块通过读 ZoneMap 索引发现,最大值是 100101,整个数据块都满足条件,那么直接从 ZoneMap 中取得 sum 结果作为第一个数据块的聚合结果,不需要读取和解压数据块。而第三个数据块 ZoneMap 记录的最小值都不满足过滤条件,所以第三个数据块直接排除。最终只需要解压、过滤和聚合第二个数据块。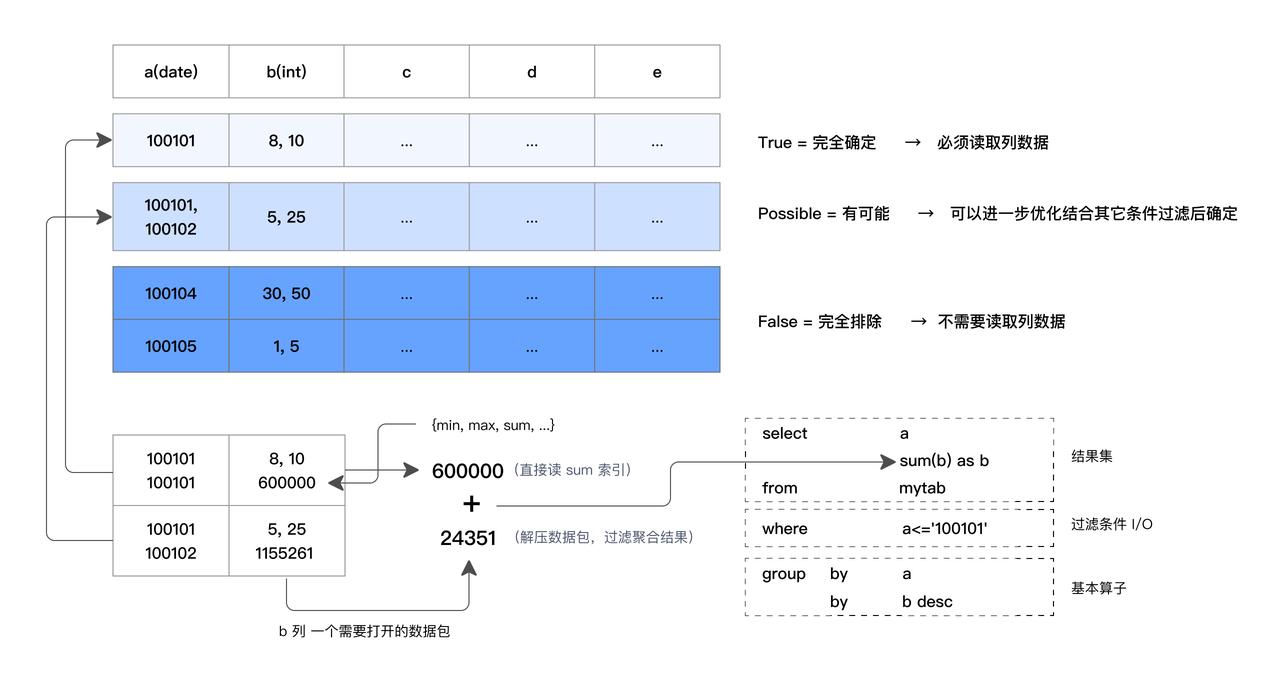
BloomFilter 索引:将索引对应列的可能取值存入 BloomFilter 数据结构中,它可以快速判断一个值是否在 BloomFilter 里面,并且 BloomFilter 存储空间占用很低。对于等值查询,如果判断这个值不在 BloomFilter 里面,就可以跳过对应的数据文件或者数据块减少 I/O 加速查询。
NGram BloomFilter 索引:用于加速文本 LIKE 查询,基本原理与 BloomFilter 索引类似,只是存入 BloomFilter 的不是原始文本的值,而是对文本进行 NGram 分词,每个词作为值存入 BloomFilter。对于 LIKE 查询,将 LIKE 的 pattern 也进行 NGram 分词,判断每个词是否在 BloomFilter 中,如果某个词不在,则对应的数据文件或者数据块就不满足 LIKE 条件,可以跳过这部分数据减少 I/O 加速查询。
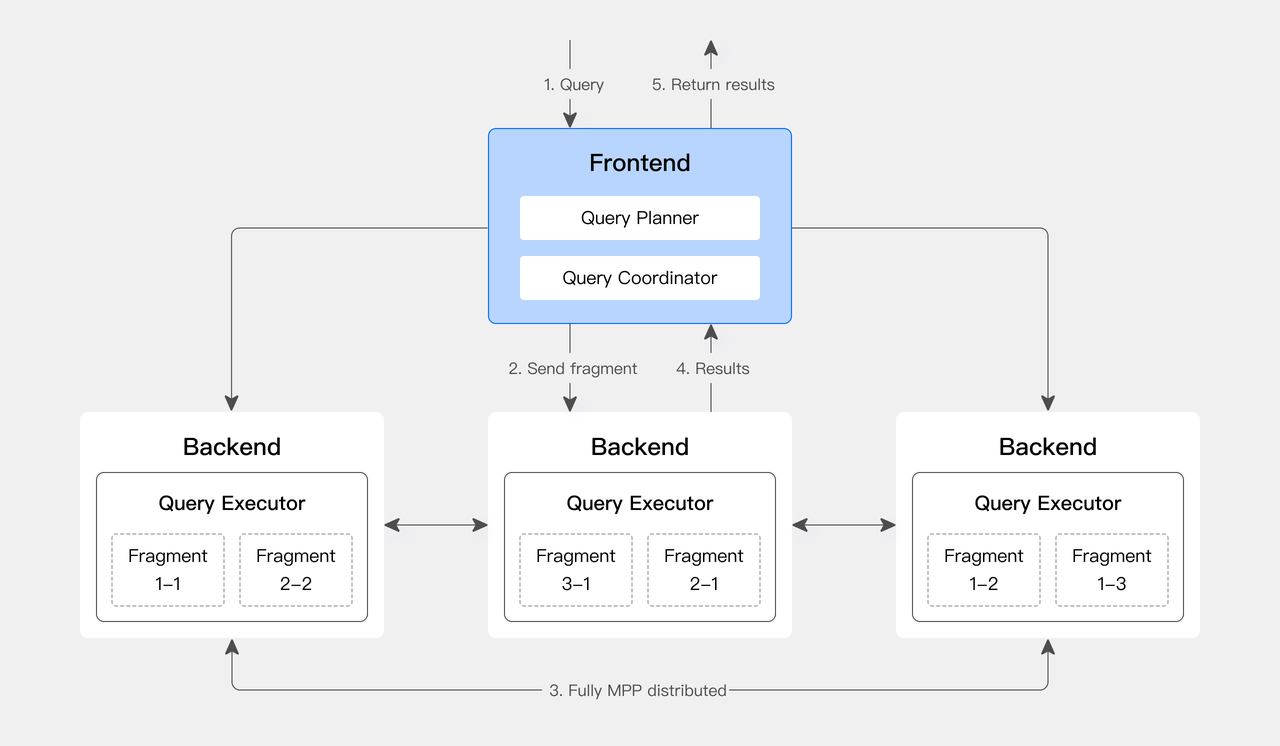
2.1.3 MPP 架构
Doris & SelectDB 采用大规模并行处理(MPP)架构,一个 SQL 会被拆分成多个执行分片,分发到不同的机器上并行执行,节点内还支持多核的并行执行,将集群资源利用最大化。对于多张大表的 Join 操作,能够通过 Shuffle 机制将数据打散到多个节点上进行,从而有效应对复杂查询。
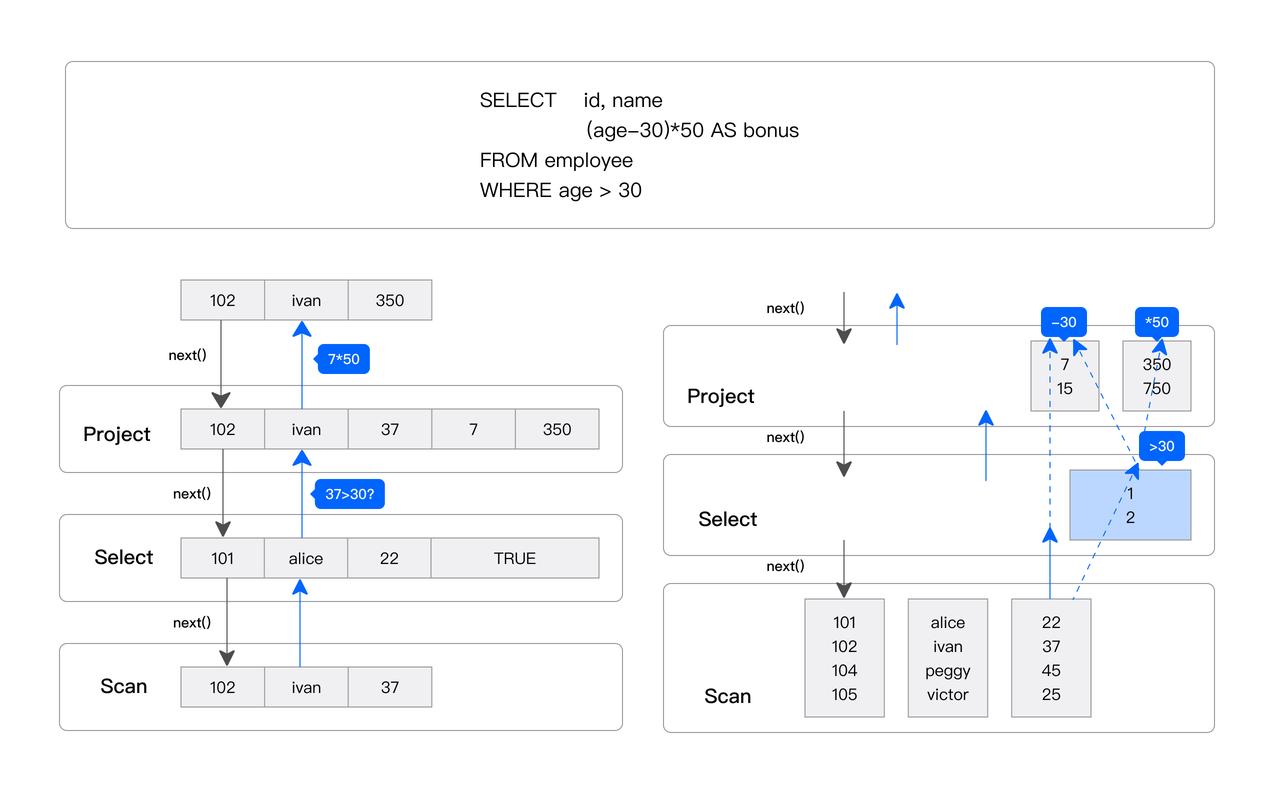
2.1.4 向量化引擎
Doris & SelectDB 查询引擎是向量化引擎,所有内存结构均按列式布局。它一次处理一批数据,而非逐条处理,可显著减少虚函数调用、提高缓存命中率,并有效利用 SIMD 指令、充分采用延迟物化技术,进一步优化性能。比如下面一条 SQL ,左侧是传统的逐行处理的火山模型引擎,右侧是 Doris & SelectDB 纯向量化 + 延迟物化处理引擎,一次处理一个批量,在拼算子性能的宽表聚合场景下,向量化引擎带来的性能提升多达 5-10 倍。
2.1.5 PipeLine 执行
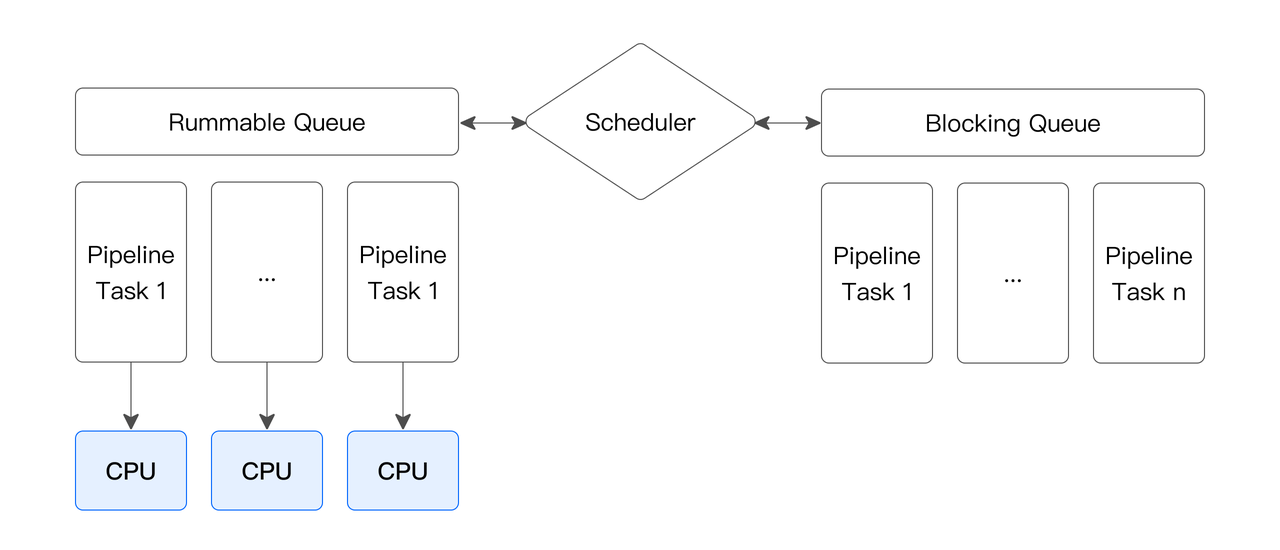
采用 Pipeline 执行机制,该技术主要通过减少阻塞,数据流驱动的方式,以高并发原理充分提高查询和数据处理的效率。其核心思想是将复杂的查询或数据处理任务分解为多个阶段或操作(称为 PipeLine Task),每个阶段负责处理数据的某个特定部分,例如过滤、投影、聚合或排序,通过并行或重叠执行这些步骤来加速整体处理过程。
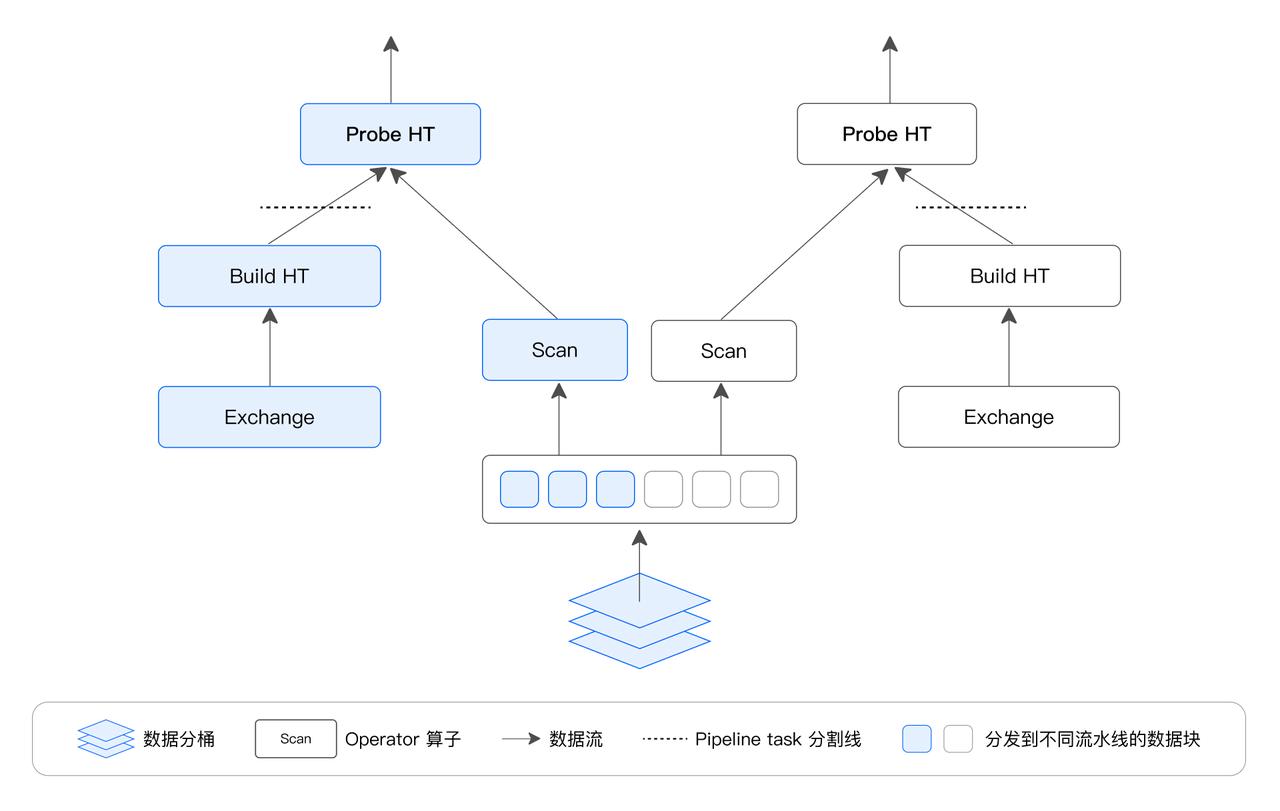
Pipeline 执行模型通过阻塞逻辑将执行计划拆解成 Pipeline Task,将 Pipeline Task 分时调度到线程池中,实现了阻塞操作的异步化,解决了 Instance 长期占用单一线程的问题。同时,可以采用不同的调度策略,实现 CPU 资源在大小查询间、不同租户间的分配,从而更加灵活地管理系统资源。Pipeline 执行模型还采用了数据池化技术,将单个数据分桶中的数据进行池化和重分布,从而解除分桶数对 Instance 数量的限制,提高其对多核系统的利用能力,同时避免了线程频繁创建和销毁的问题,提高了系统的并发性能和稳定性。
2.1.6 智能优化器
Doris & SelectDB 采用 Cascades + Dphyper 混合智能枚举框架,优化大规模查询计划,并结合基于规则的和基于代价的查询改写、函数依赖优化及分布式执行优化,提升查询性能。同时,通过精准统计信息与动态调优,增强对业务场景的适配性,确保高效查询执行。

- Cascades 和 Dphyper 混合智能枚举框架 : Doris & SelectDB 优化器基于 Cascades 自顶向下枚举框架,具备解耦、易扩展和提前剪支的优势。为优化枚举空间,采用 project 规范化和 group 合并策略,避免无效计划膨胀。对于 8 张表以内的查询,进行完整的 Cascade 枚举,并引入 Dphyper 算法覆盖 8-64 张表规模,通过图简化降低枚举成本,确保高效查询优化。总体而言,Doris & SelectDB 的 Cascades + Dphyper 混合枚举框架,能够支持 64 张表的大规模复杂查询,提供卓越性能保障。
- 基于代价和规则的查询改写:支持丰富的改写能力包含谓词下推、常量折叠、分区/列裁剪、外连接消除、谓词推导、子查询提升、Limit 下压、物化 CTE、窗口函数消除子查询、Set 算子 Distinct 推导、Distinct 下压、OR-expansion 等。
- 基于 FD 等属性信息的优化:其优化器维护了多种逻辑属性,如函数依赖、唯一性、均匀性和等值集合等,以支持多种优化规则的执行。例如,基于函数依赖属性,Doris & SelectDB 优化框架能够实现如 Group By Key/Order By Key/Join Elimination 等高效优化,从而显著减少查询计算量,大幅提升查询性能。
- 深度的分布式查询优化: Doris & SelectDB 在分布式查询优化方面进行了深度优化。除了支持传统的高效连接算法,如 colocate join 和 bucket shuffle join 外,还通过分析中间结果数据的分布特性,增强了聚合、连接和窗口函数等分布式查询计划,能够智能识别数据特征,避免无效的数据重分布,从而提升查询性能。
- 精准的统计信息管控和动态调优: 主流优化器依赖统计信息和代价模型选择最优执行计划,但在频繁更新的数据场景或数据湖中,静态统计信息易失效,影响计划质量和查询性能。Doris & SelectDB 通过精准控制统计信息的时效性,避免采集无效数据,防止低效计划生成。此外,在缺乏列统计信息时,采用启发式连接重排优化查询,提升数仓及数湖场景适配性。同时,也在引入历史执行反馈(HBO),实现统计信息校准和动态调优,进一步优化查询性能。
2.1.7 物化视图
在数据分析中,物化视图采用空间换时间的策略,提供了有效的查询加速方案,兼具视图的灵活性和物理表的高性能。它可以预先计算并存储查询结果集,从而在查询请求到达时直接从物化视图中获取结果,而无需重新执行查询语句。这种机制有效提升了查询性能,降低了重复执行查询的开销。
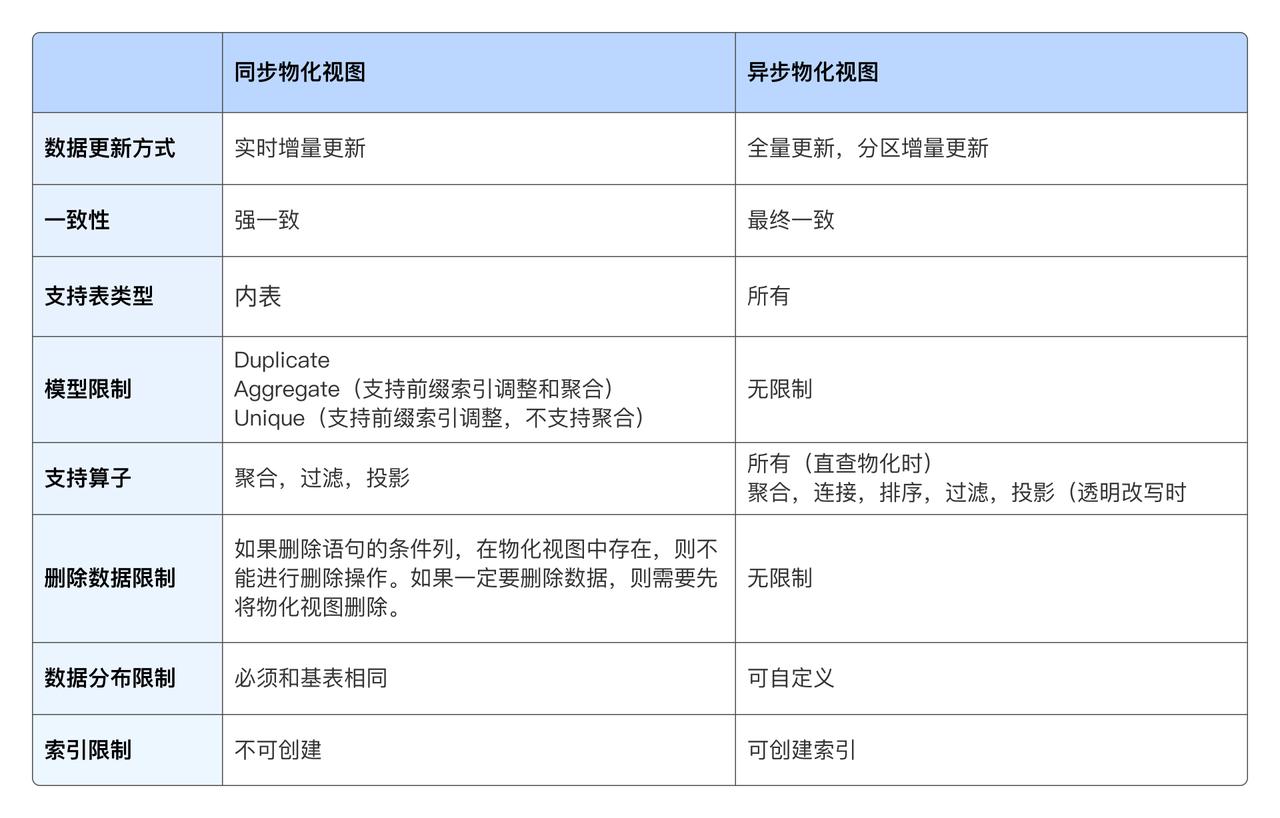
Doris & SelectDB 支持两种物化视图:同步物化视图和异步物化视图。 前者能够保持物化视图和基表数据同步一致,但只支持单表,适合单表聚合查询的分析加速。后者能够支持多表以及复杂查询,但是物化视图更新滞后于基表(两者最终一致),并支持对多表物化视图的手动刷新和按照分区级别增量自动更新。下面对其物化视图特性和适用场景的总结:
2.1.8 多级缓存
缓存技术是有效的加速手段,Doris & SelectDB 支持多级缓存机制:SQL 的最终结果、聚合结果缓存、原始数据缓存、存算分离和数据湖分析场景下的本地文件缓存。通过多级缓存机制,能够最大程度实现数据的复用,减少不必要的执行和 IO,最大化系统性能。
- SQL Cache : 用于缓存 SQL 查询的结果,特别适用于重复执行相同查询的场景,例如报表生成或仪表盘应用。它根据 SQL 签名、查询表的分区 ID 以及分区的最新版本来缓存结果。只有当 SQL 语句完全一致时,缓存才会命中。这种缓存特别适合更新频率不高的场景(比如 T+1),对于实时更新场景,尽管支持,但是命中率可能较低。
- Query Cache(聚合结果缓存 ):在处理聚合查询时,都会将本地聚合的中间结果缓存于内存中。这样,当后续收到相同或类似的聚合查询时,能够直接从 Query Cache 获取匹配的聚合结果,无需再次从磁盘读取并计算数据。
- Page Cache : 使用内存来缓存最近频繁读取的数据,这里面缓存的都是经过解压之后的数据,这种缓存在优化 IO 的同时,也避免了 CPU 的解压开销。在高并发查询场景下,优化效果尤为明显。
- File Cache : 在存算分离和数据湖分析场景下,File Cache 通过缓存最近访问的远程存储系统(如 HDFS 或对象存储)中的数据文件来加速查询,减少频繁从远程获取数据的昂贵开销。文件缓存将数据块存储在 Backend(BE)节点本地,并使用 LRU(最近最少使用)策略管理空间,显著提升了热点数据的查询性能和稳定性。
2.1.9 分区分桶
**Doris & SelectDB 支持两层数据划分:分区和分桶。**通过分区分桶机制能够有效将数据和负载划分到多个节点上,以提升系统的扩展性和并行处理能力,与此同时也有利于对查询进行分区分桶裁剪,减少非必要的数据扫描,从而提升系统的性能和高并发处理的能力。如下图所示,以下查询通过分区键 day裁剪掉不相关分区,通过分桶键id裁剪掉不相关分桶。
SELECT * FROM user_table
WHERE id = 5122 and day = '2022-01-01';

2.1.10 聚合模型
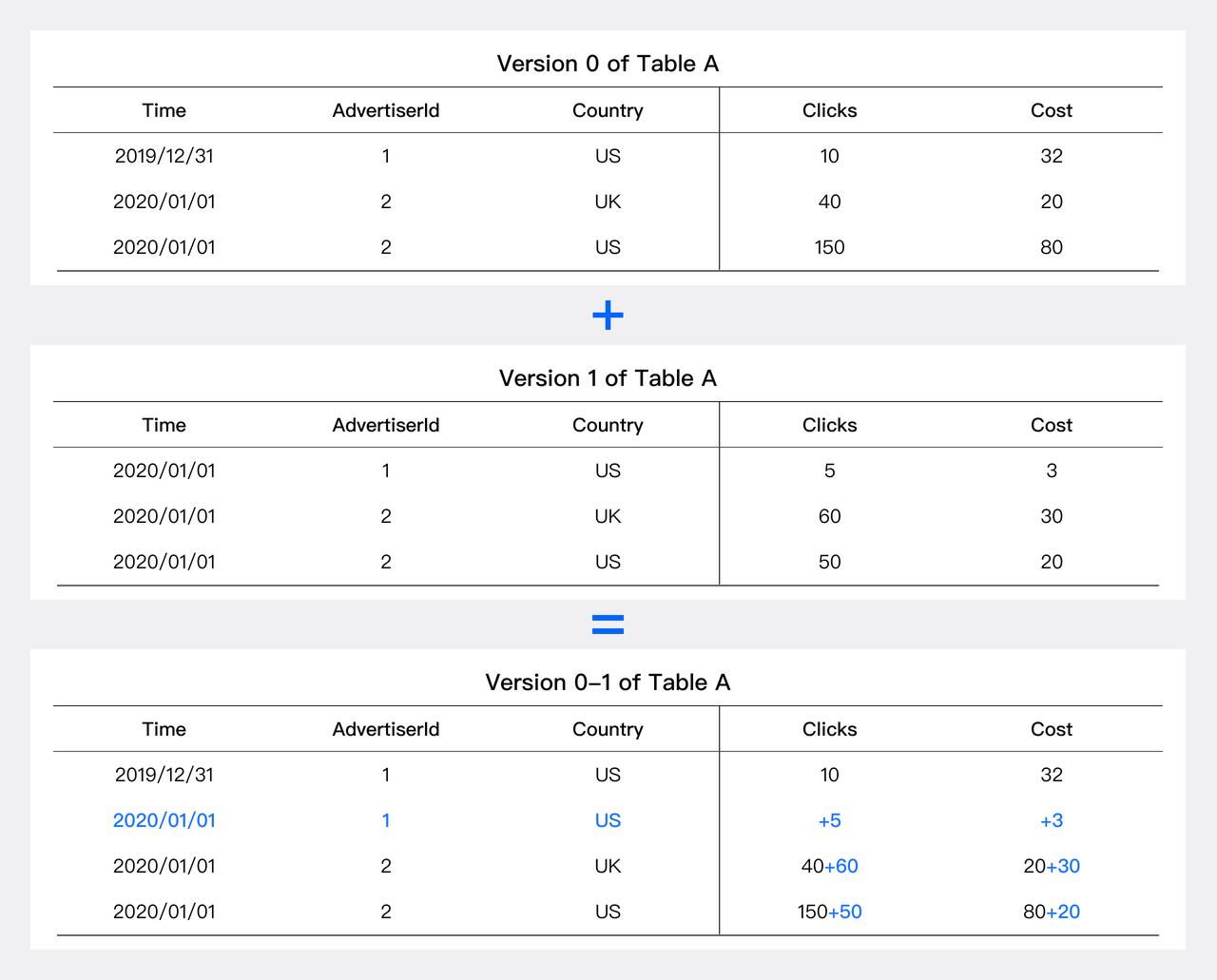
Doris & SelectDB 支持多种表模型,其中聚合模型是一种表模型,允许用户在建表时指定聚合键(Aggregate Key)和聚合函数。在数据导入过程中,会根据聚合键对数据进行分组,并对每个分组应用指定的聚合函数进行预聚合。预聚合后的结果会被存储,查询时可以直接使用这些结果,而无需在运行时扫描和计算原始数据,从而优化查询性能。这一技术通常被应用在一些指标分析的场景中。
2.1.11 高并发点查优化
在高并发点查的 DataServing 场景,Doris & SelectDB 特别做了几项优化,使得高并发点查的单节点 QPS 提升到万级别,并且可以随着节点数线性扩展,具体来说:
- 行列混合存储: 针对点查询需求,支持在列式存储基础上另存行存格式数据,整行数据可直接读取,减少单次点查询的随机 I/O 放大问题。
- 点查询短路径优化(Short-Circuit Path): 跳过传统 MPP 查询框架的复杂调度流程,直接通过轻量级执行计划(Short-Circuit Plan)快速返回结果。例如,FE 解析 SQL 后,若查询符合条件(如基于主键的等值查询),直接生成短路径计划,减少 FE 资源消耗和网络开销。
- 预处理语句(Prepared Statement): 复用已解析的 SQL 结构和表达式,避免重复解析。例如,高并发场景下,FE 通过会话级缓存存储预处理语句,降低 CPU 开销,提升吞吐量。
2.2 实时
2.2.1 实时导入
数据从产生到能够进入到 Doris & SelectDB 进行分析的实时性要求越来越高,尤其是在电商实时大屏、物联网设备监控、金融分控系统等业务中。其提供了多种实时数据导入的机制,并且也在持续优化底层技术,来达到更好的时效性和并发吞吐。
- 流式同步:通过实时数据流(如 Flink、Kafka、事务数据库)将数据实时导入到 Doris & SelectDB 表中,适用于需要实时分析和查询的场景。
- 可以使用 Flink Doris Connector 将 Flink 的实时数据流写入到 Doris & SelectDB 表中。
- 可以使用 Routine Load 或者 Doris Kafka Connector 将 Kafka 的实时数据流写入到 Doris & SelectDB 表中。
- 可以使用 Flink CDC 或 Datax 将事务数据库的 CDC 数据流写入到 Doris & SelectDB 中。
- Stream Load:导入本地文件或者程序通过 HTTP 写入数据到 Doris & SelectDB 中,既能够保证时效性也能够保证高吞吐,最快可达到秒级别可见。
- 数据集成工具导入:DTS、DataWorks 等数据集成工具也支持集成数据到 SelectDB
此外,还支持通过 JDBC INSERT 方式实时写入数据,但该方式吞吐不优并不推荐。对于大批量数据写入和高吞吐场景支持其他机制,包括通过数据湖 Insert Into Select 方式或 Broker Load 方式,来批量导入 HDFS 或对象存储上的数据。
为保障实时导入效率,其进行了多项技术创新:
- Group Commit 事务合并: 将多个小批量写入合并为单个事务提交,减少事务开销,显著提升高并发写入性能。
- MemTable 前移优化: 在写入协调端进行 MemTable 的构建,减少数据编码次数和优化内存反压策略,降低写入延迟并提升稳定性
2.2.2 实时更新
在实时数据仓库的业务场景中,支持数据的实时更新是核心能力之一。例如在数据库同步(CDC)、电商交易订单、广告效果投放、营销业务报表等业务场景中,面对上游数据的变化,通常需要快速获取到变更记录并针对单行或多行数据进行及时变更,保证业务分析师及相关分析平台能快速捕捉到最新进展,提升业务决策的及时性。
传统的大数据分析系统解决这类问题通常比较吃力,很多系统只能做到分区级别的更新。Doris & SelectDB 针对实时数据更新做了系统性优化,相比于传统的 Merge-on-Read 或者 Copy-on-Write 的方案,Doris & SelectDB 采用的 Merge-on-Write 的方案使用记录删除标记和更新增量的方式,在查询性能和更新性能方面取得了最佳平衡。
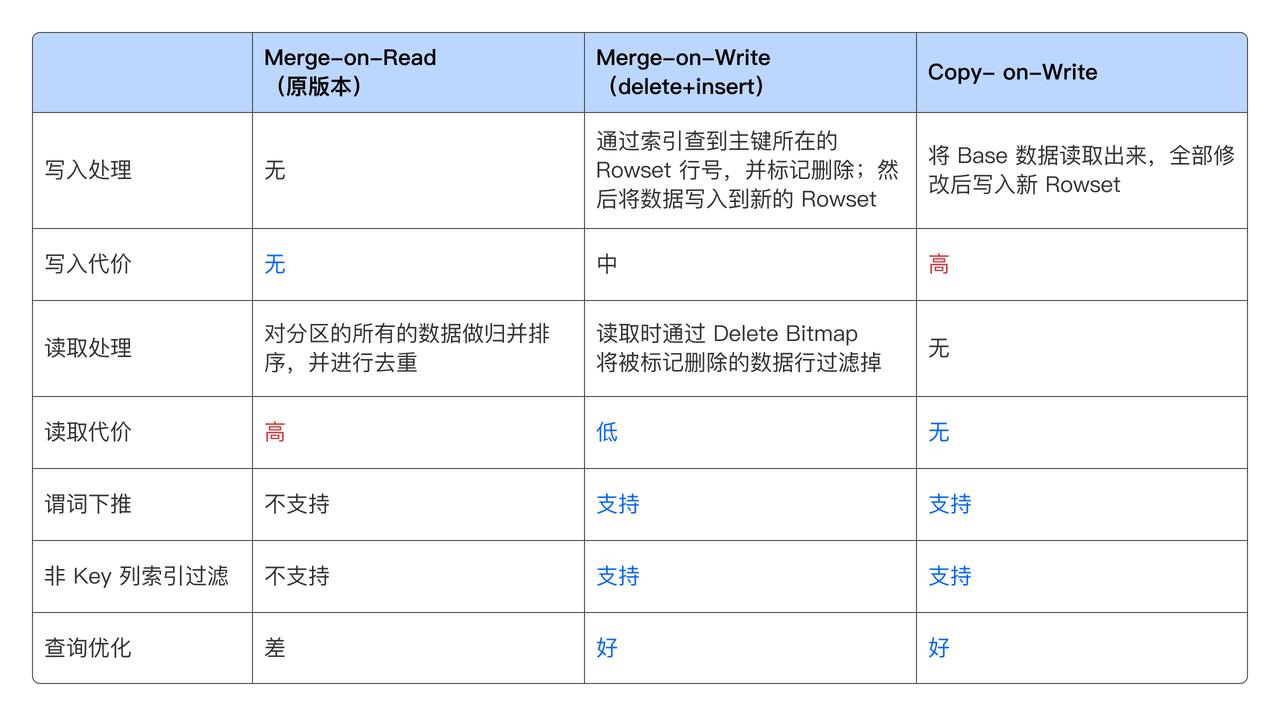
除了整行更新的模式,Doris & SelectDB 也支持部分列更新的模式,进一步优化了使用体验。
2.3 云原生
云计算基础设施的成熟带来了许多独有的优势,例如可根据需要快速增加或减少资源,无需担心基础设施的限制,只需为实际使用付费;又如提供了灵活多样的存储介质,可针对实际需求配置不同性能、不同价格的存储。SelectDB Cloud 采用存算分离模式,将计算资源和存储资源分开管理,从而更好地发挥云计算平台的强大功能。 此外,Apache Doris 及 SelectDB Enterprise 在 3.0 版本开始也支持了存算分离架构。
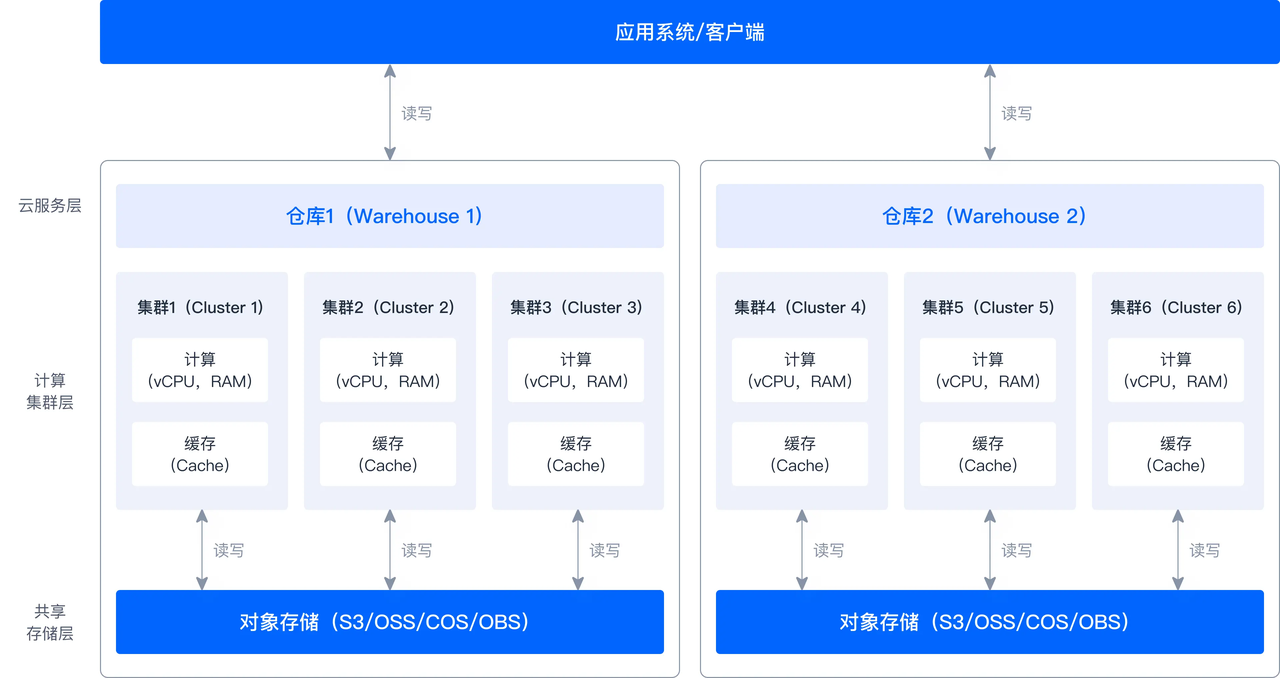
- 更低成本:与存算一体架构相比,存算分离架构综合成本降低超 90%
- 按需付费:相较于存算一体,无需再预置计算和存储资源,存储可按实际使用付费,计算资源则可以灵活弹性扩展。
- 单副本存储:数据仅需在低成本的对象存储中存储一份副本,而不再在高成本的块存储中存储三个副本。热数据则缓存于块存储中,这不仅降低了存储量和硬件资源需求,还显著降低了存储成本(例如,云厂商的云盘价格通常是对象存储的数倍),同时保证了查询性能。
- 资源消耗降低:Compaction 操作所消耗的资源和副本数量成正比,在存算分离模式下只需要处理单一数据副本,资源消耗大幅减少。
- 极致弹性:得益于无状态的计算节点设计,能够更加灵活地应对不断变化的业务需求,提供高效、弹性的计算资源管理
- 弹性扩缩容:支持灵活调整计算资源,更好应对业务高峰或波动。当系统负载增加时,计算节点可以迅速扩容;而在需求减少时,计算资源又可以灵活缩减,从而避免不必要的资源浪费。
- 计算节点按需分配:支持将不同配置的计算节点灵活分配到各计算组中,根据任务需求精确分配资源。例如,高性能计算节点被用于复杂查询或高并发场景,而标准配置节点分配于简单查询或低频请求。
- 负载隔离:提供高效的资源管理和负载隔离,为不同业务需求提供精细化的计算资源调度
- 业务间负载隔离:针对不同业务需求,可为每业务配置独立计算组,并实现物理隔离。确保各业务计算任务在专用资源上运行,减少相互干扰,保障系统的稳定性和高效性。
- 离线负载隔离:对于大规模离线数据处理任务,可将其分配到特定的计算组,使用低成本的资源进行批量数据处理,而不影响实时业务的计算性能。
- 读写隔离:可分别为读、写操作创建计算组和用户。写计算组专门处理数据写入(插入、更新等),而读计算组专门处理查询请求,确保在线业务的查询延迟稳定。
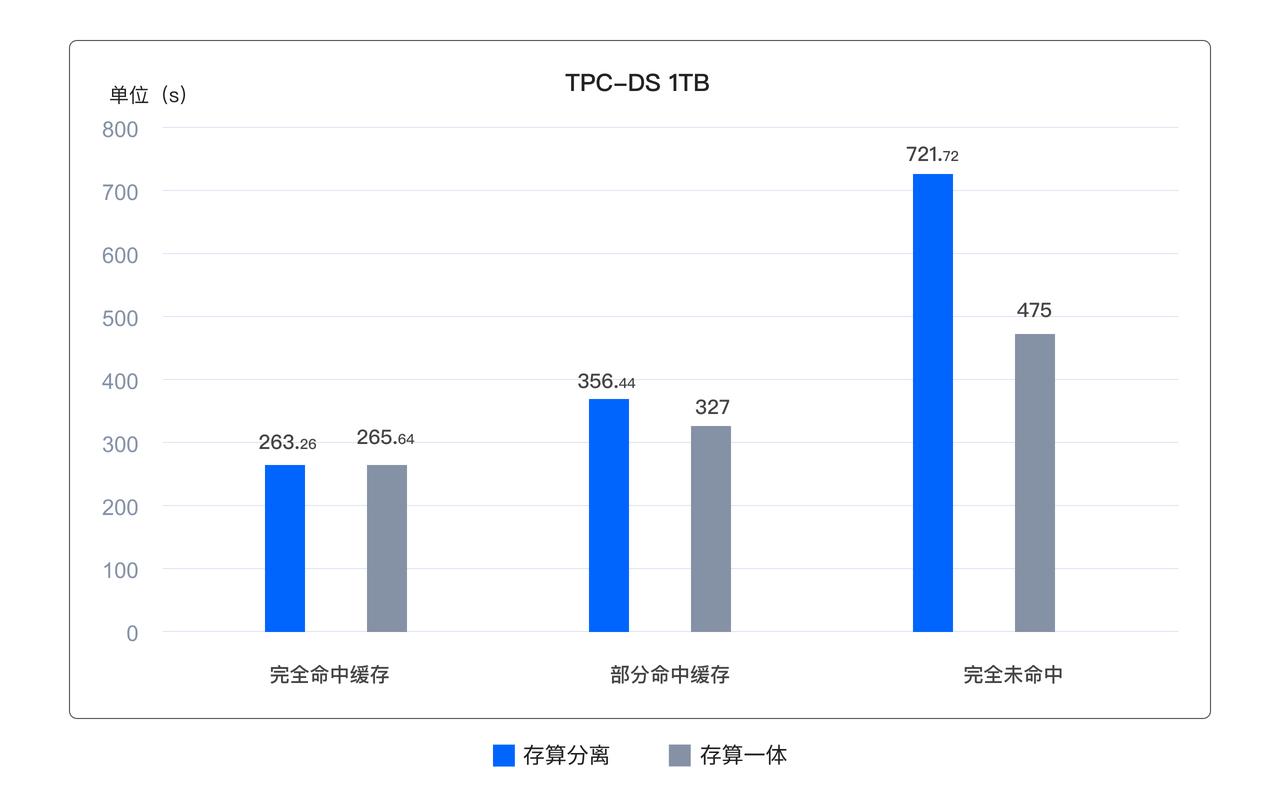
在存算分离的架构中,数据需要从远端共享存储系统中读取,是否会对查询性能造成影响是客户普遍关注的问题。为了加速数据访问,Doris & SelectDB 实现了基于本地磁盘的高速缓存机制,并提供 LRU 和 TTL 两种高效的缓存管理策略,并对索引相关的数据进行了优化,旨在最大程度上缓存用户常用数据、提升查询性能,并且能够在多 Cluster 之间推送缓存,实现主动预热。在实际的评测中,只要缓存配比合理,性能并未明显降低。即使在没有 Cache 完全从对象存储冷读的场景下,性能损失也只有 35%左右,相比业界同类系统有显著优势。
2.4 湖仓融合
除了将数据导入到 Doris & SelectDB 内进行高效分析外,Doris & SelectDB 还可以当做一个湖仓的计算和查询(Data Lakehouse Compute & Query Engine)直接对位于 Data Lakehouse、数据库、离线数据仓库中的数据进行计算和查询,在不进行数据移动的情况下,打通湖仓和数据库的边界,实现统一的查询加速和多源联邦分析,达到数据无界、湖仓融合的效果。
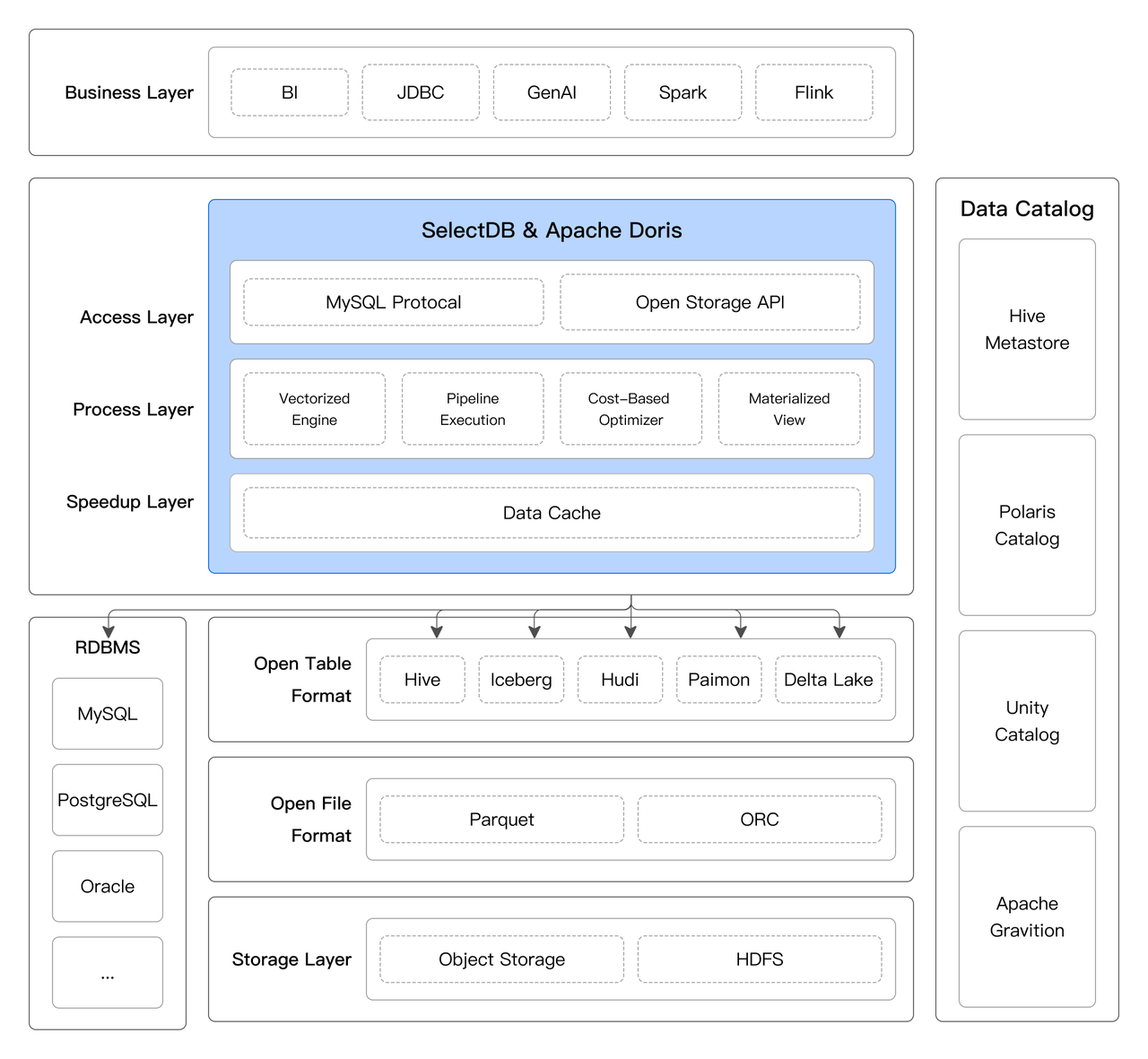
2.4.1 全面的数据打通
Doris & SelectDB 通过 Multi-Catalog 和 可扩展的连接器框架,支持主流数据系统和数据格式,并提供基于 SQL 的统一数据分析能力,用户能够在不改变现有数据架构的情况下,轻松实现跨平台的数据查询与分析。
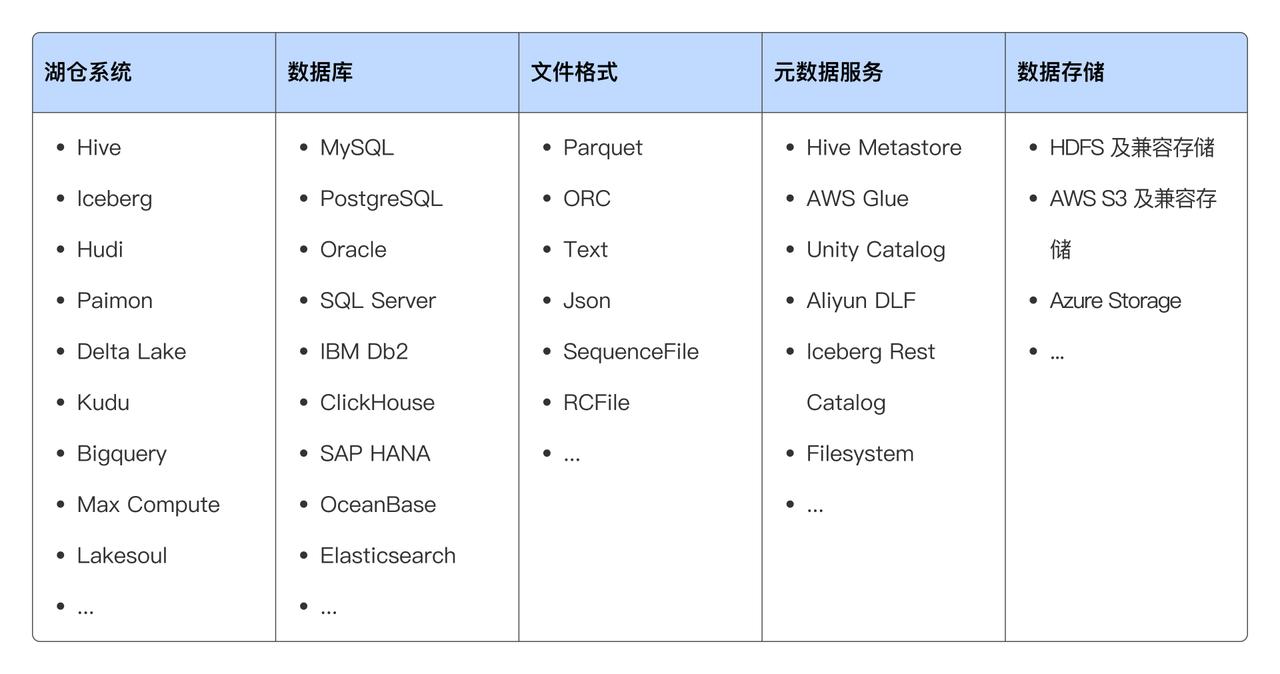
2.4.2 湖仓加速效果
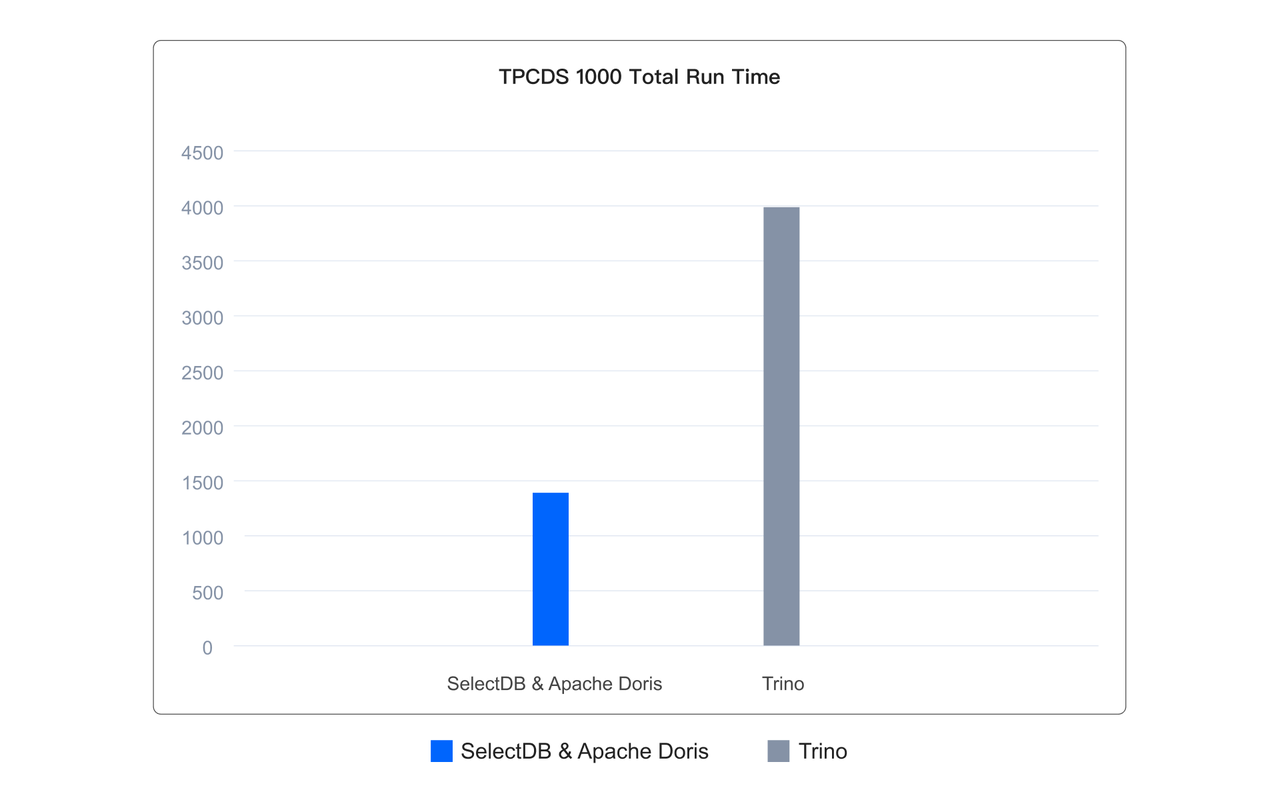
得益于上面提到的各种极速查询的技术,当使用 Doris & SelectDB 作为湖仓计算和查询引擎的时候,相比 Presto、Trino、SparkSQL、Hive 等引擎,通常有数倍的性能提升,如下所示,在基于 Iceberg 表格式的 1TB 的 TPCDS 标准测试集上,其执行 99 个查询的总体运行耗时仅为 Trino 的 1/3。
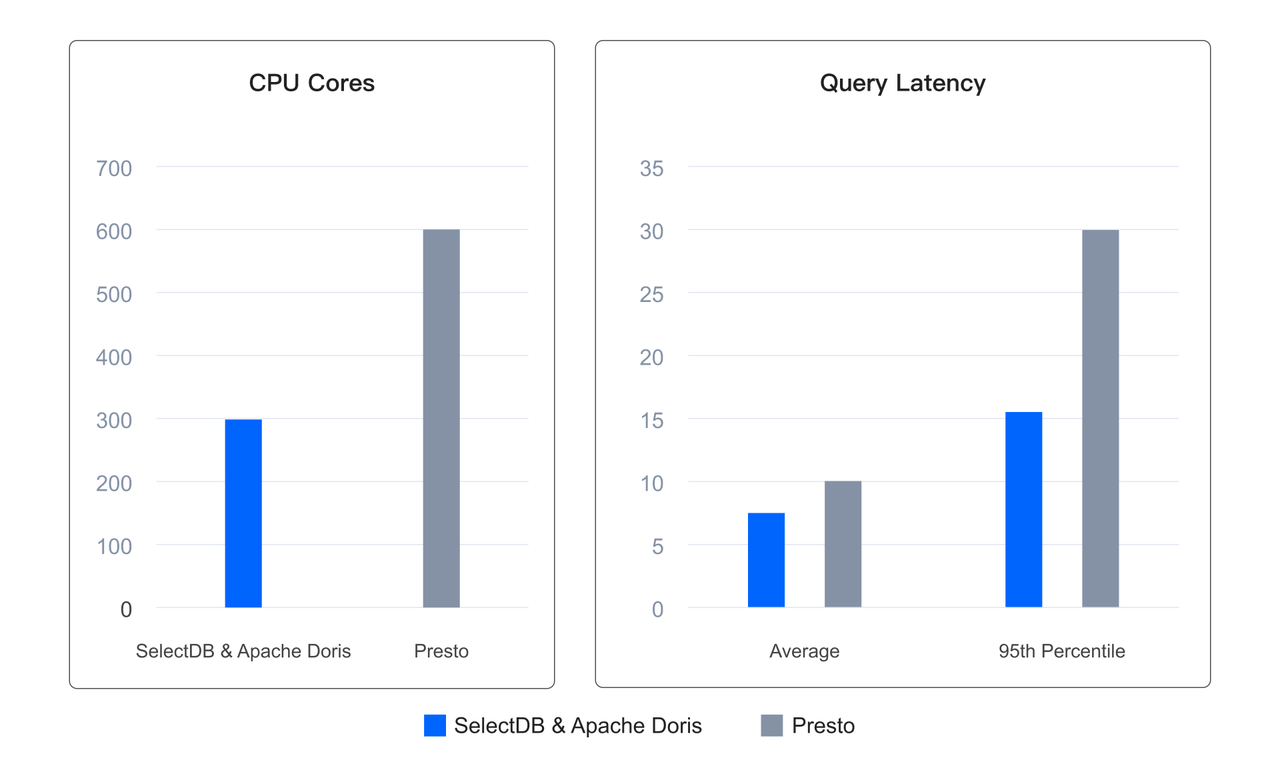
实际用户场景中,在使用一半资源的情况下,相比 Presto 平均查询延迟降低了 20%,95 分位延迟更是降低 50%,达到了降本增效的目的。
2.4.3 多 SQL 方言的兼容
在企业整合多个数据源并实现湖仓一体转型的过程中,迁移业务的 SQL 查询到 Doris & SelectDB 是一项挑战,因为不同系统的 SQL 方言在语法和函数支持上存在差异。若没有合适的迁移方案,业务侧可能需要进行大量改造以适应新系统的 SQL 语法。
为了解决这个问题,Doris & SelectDB 提供了 SQL 转换服务,允许用户直接使用其他系统的 SQL 方言进行数据查询。转换服务会将这些 SQL 方言转换为 Doris & SelectDB SQL,极大降低了用户的迁移成本。目前,已支持 Presto/Trino、Hive、PostgreSQL 和 Clickhouse 等常见查询引擎的 SQL 方言转换,在某些实际用户场景中,兼容率可达到 99%以上。
2.4.4 湖仓融合建模
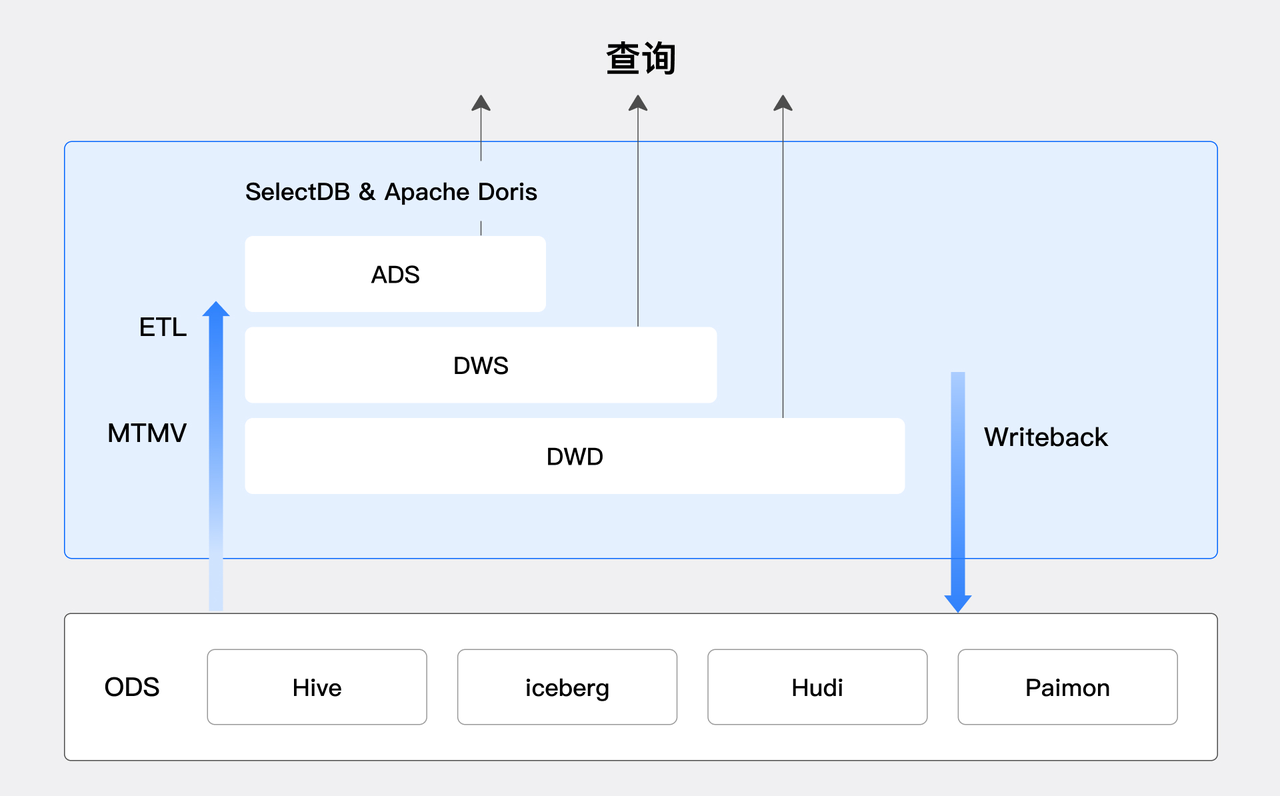
数据分层建模,ODS 层在 LakeHouse 中,DWD,DWS,ADS 层的数据加工和数据服务在 Doris & SelectDB 中,充分利用其性能优势,此外还可以将其加工好的数据再通过 Write-Back 的机制写回到 LakeHouse 中,实现备份归档或者供其他的数据系统继续处理使用。
2.5 多模数据分析
现代化的数据分析系统,除了能够高效的处理结构化的数据,也应该能够高效的存储和处理半结构化数据和非结构化数据:
- 半结构化数据: 半结构化数据虽然拥有一定的结构,但不严格固定,具有很强的灵活性。比较典型的是 JSON 格式,可以便捷地增加新字段或删除不需要的字段,而日志、Trace、Metrics 是最典型的 JSON 格式半结构化数据。本章节将聚焦在高效的 JSON 数据分析和高性价比的可观测性分析方案(基于日志、Trace、Metrics )。
- 非结构化数据:非结构化数据指没有固定结构的数据,例如文本、音频和视频等,这类数据缺乏明显的结构特征。针对非结构化数据的分析操作通常是检索(Search),比如在大模型 GenAI 的 RAG 中通常包含两类:
- 文本检索:在文本中查找特定的关键字或短语,Doris & SelectDB 提供了倒排索引等功能,可以实现对非结构化文本数据的高效检索,包括关键词检索、短语检索等。
- 向量检索:将非结构化数据转化为高维向量,并在向量空间中计算相似性以实现高效检索,目前也在增强这方面的能力。
2.5.1 高效 JSON 存储分析方案 - VARIANT
JSON 格式数据的处理面临如下几个挑战:
- 如何支持灵活的 Schema:字段随着业务发展而增加/减少,类型也可能变化,数据中的嵌套结构也让字段变的更加复杂,因此要求数据库能够支持灵活的 Schema。
- 如何高效存储:大量重复的自描述内容,比如大量重复的字段名,通常是由机器产生。如果按原始数据存储,数据冗余存储带来的资源浪费非常高,因此要求数据库能够高效存储。
- 如何极速分析:半结构化数据通常为文本形式,直接对文本解析和分析虽然可行但性能较差。特别是在分组、聚合、过滤等操作时,要从大量的字段中分析其中的几个字段,将带来很多不必要的 IO 和解析开销。
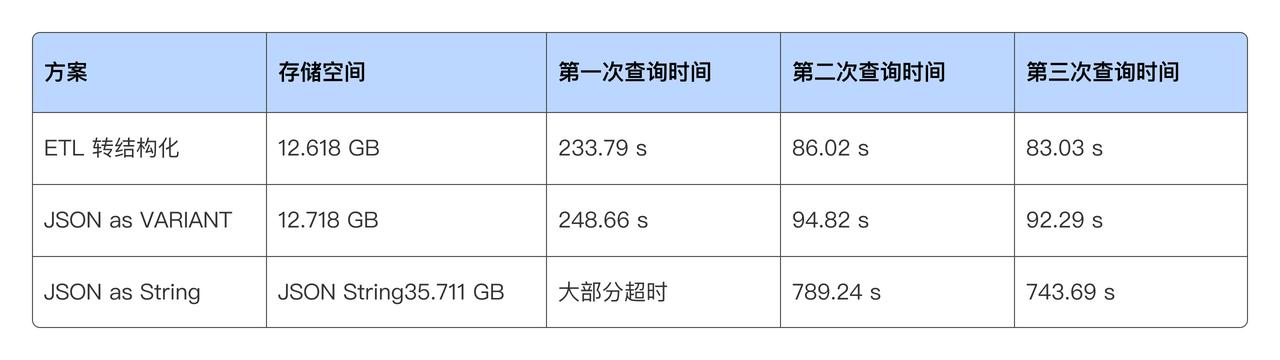
业界惯常的做法是将 JSON 存储成 String,并且支持丰富的处理函数,这种方案能够解决灵活 Schema 的问题,但是存储和分析效率都非常低。
为此,推出了 VARIANT 数据类型,VARIANT 数据类型可以存储任何合法的 JSON,可自动从 JSON 中抽取字段并推断其类型;并将这些字段存储为 VARIANT 列的子列,这些子列以列存的方式存储,能够高效压缩存储;这种列式存储方式使得 VARIANT 具备很好的分析性能,当进行聚合/过滤/排序等查询时,只需要读取 VARIANT 子列数据即可,不会产生额外的数据解析开销,查询性能可获得数量级的提升。VARIANT 的方案使得半结构化数据处理效率逼近结构化数据,同时又满足了灵活性的目的。
2.5.2 高性价比可观测性分析方案
日志、Trace、Metrics 是最典型的 JSON 格式半结构化数据,而这些数据是可观测性分析的主要内容。这类数据具有高写入吞吐、海量存储和实时响应需求,所以需要一个高性价的方案。
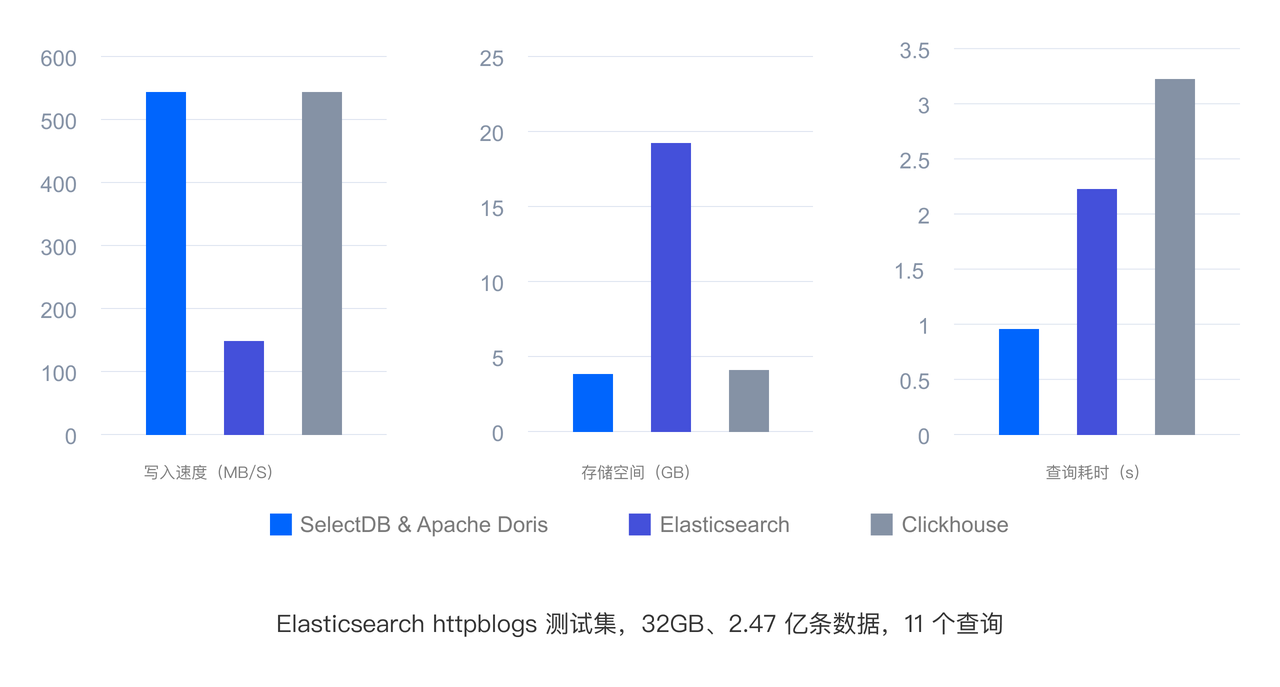
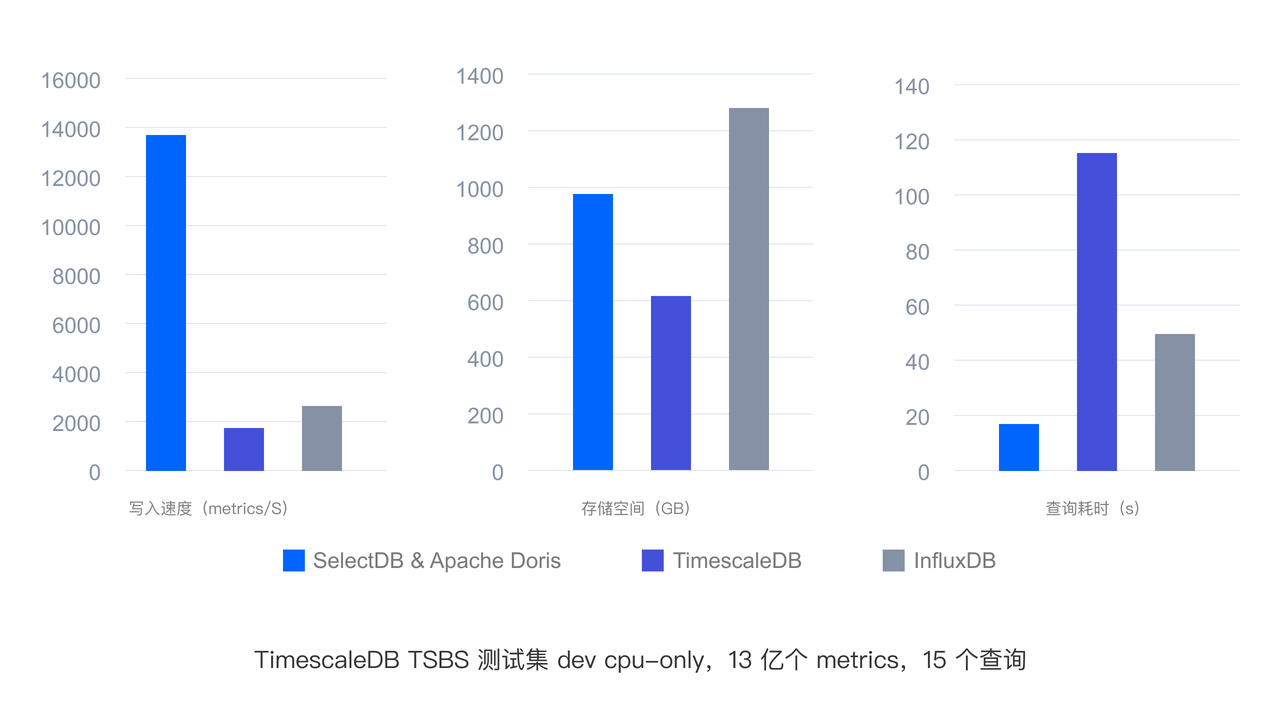
通过一系列的技术优化,使得在 Log Trace 相对于 ElasticSearch 写入性能 3~5 倍,80% 存储空间降低,查询性能 2~3 倍;相对 CK 查询性能 3 倍。Metrics 相对于 TimescaleDB InfluxDB 写入性能 5~7 倍,查询性能 2~6 倍。
- 提升写入吞吐量
- 使用 SIMD 指令和 CPU 向量指令加速数据解析和索引创建。
- 移除不必要的正向索引,简化索引创建过程。
- 降低存储成本
- 移除占索引数据 30% 的正向索引。
- 采用列式存储和 ZSTD 压缩算法,压缩比达 5:1 到 10:1
- 采用存算分离、冷热数据分层存储机制,将历史日志存储于低成本介质。
- 高性能查询引擎 : 除之前介绍的极速分析,还对可观测性场景下常用的 TopN 做了动态剪枝优化
- 高性能日志全文检索分析:支持倒排索引和全文检索,日志场景常见查询(关键词检索明细、趋势分析等)秒级响应。
- 标准 SQL 接口: 学习成本低,简单易用,快速上手。
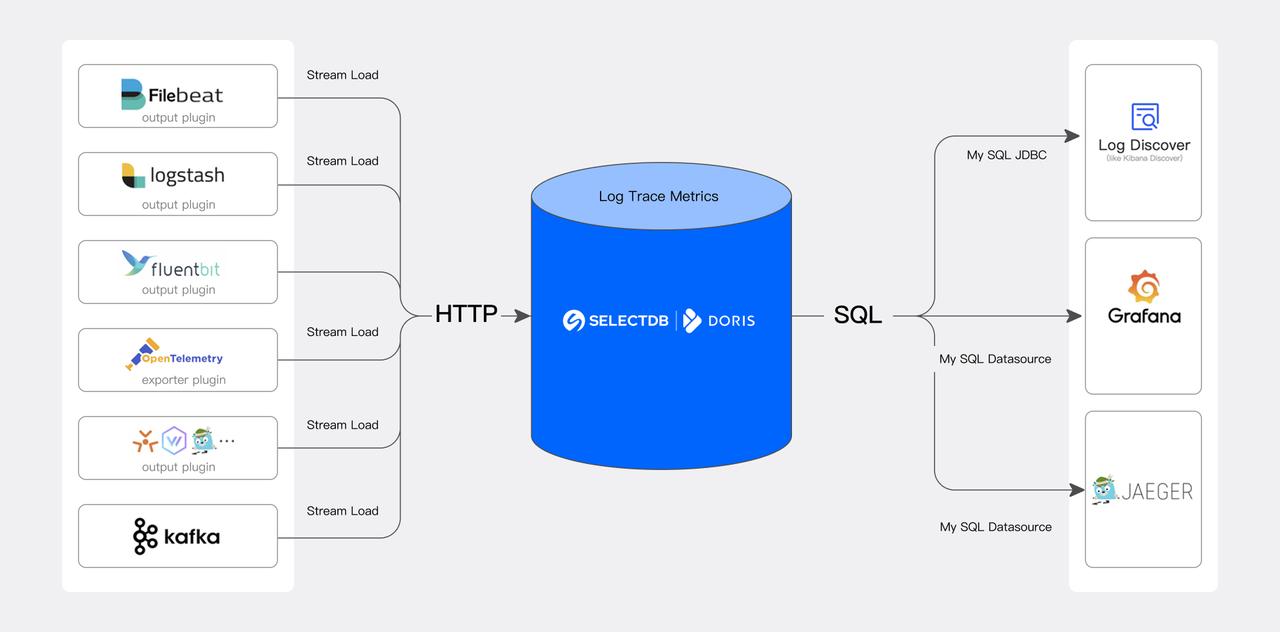
- 开放、易用的上下游生态: 上游通过 Stream Load 通用 HTTP APIs 对接常见的日志采集系统和数据源 Logstash、Filebeat、Fluentbit、Kafka 等,下游通过标准 MySQL 协议和语法对接各种可视化分析 UI,比如可观测性 Grafana、BI 分析 Superset、类 Kibana 的日志检索 Doris WebUI。
3 结语
Doris & SelectDB 以其极速、实时、云原生、湖仓融合、高效多模数据分析的优秀能力,使得其成为实时数据分析、湖仓融合分析、可观测性与日志分析、数仓构建的最佳选择。安踏、长安汽车、顺丰科技、特步、中通快递、趣丸科技、MINISO、MiniMax、观测云、迅雷、新东方、星火保等众多客户基于 Doris & SelectDB 构建了高效的数据分析平台。未来,将持续提升其弹性的能力、批量处理能力、增量流式处理能力、面向大模型 GenAI 的混合检索能力。
如果您对 Doris & SelectDB 感兴趣,欢迎下载体验。
此外,如果你想获得即时沟通,反馈/了解产品更多信息,也可扫描下方二维码咨询/交流。



