OLAP(联机分析处理)是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。与传统的 OLTP(Online Transaction Processing,联机事务处理)系统相比,OLAP更注重数据的查询和分析性能,能够处理大量历史数据,提供快速、灵活的多维度数据分析服务。具体表现包括:
多维数据分析:OLAP 允许用户从多个角度(如时间、地区、产品等)对数据进行分析,帮助发现数据间的关联性和趋势;
快速响应:通过预计算和索引优化,OLAP 系统能够迅速响应复杂的查询请求,提供实时或近实时的分析结果;
数据汇总与聚合:支持数据的汇总和聚合操作,方便用户进行高层次的数据分析,如趋势预测、市场细分等;
OLAP 主要特点
OLAP 的主要特点是直接仿照用户的多角度思考模式,预先为用户组建多维的数据模型,在这里,维指的是用户的分析角度。一旦多维数据模型建立完成,用户可以快速地从各个分析角度获取数据,也能动态的在各个角度之间切换或者进行多角度综合分析,具有极大的分析灵活性。
OLAP 在人工智能上的实战案例分享
前景介绍
腾讯音乐娱乐集团(以下简称“腾讯音乐”)是中国在线音乐娱乐服务开拓者,有着广泛的用户基础,总月活用户数超过 8 亿,通过“一站式”的音乐娱乐平台,用户可以在多场景间无缝切换并享受多元的音乐服务。腾讯音乐希望通过技术和数据赋能,为用户带来更好的体验,为音乐人和合作伙伴在音乐制作、发行、销售等方面提供支持。
基于公司丰富的音乐内容资产,需要将歌曲库、艺人资讯、专辑信息、厂牌信息等大量数据进行统一存储形成音乐内容数据仓库,并通过产品工具为业务人员提供数据分析服务。在内容数仓搭建的过程中,降本增效为主要目的,希望在数据服务方面不断提升产品工具的开发与分析效率,同时在数仓架构方面能够有效减少架构成本与资源开销。
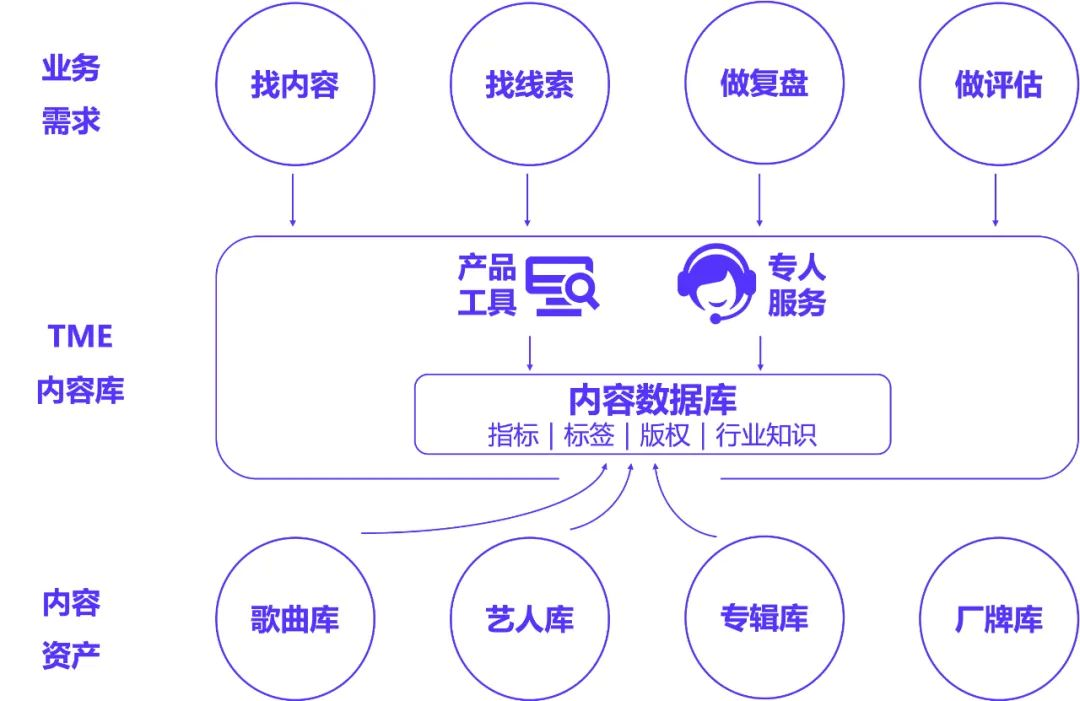
痛点
在传统数据服务中,我们为业务分析师提供了多种数据服务,包括 SQL 查询、固定看板、定制化的分析工具以及人工跑数。然而,在实际应用过程中仍然存在一定痛点:
SQL 查询平台 : 业务分析师根据需求进行 SQL 语句编写,对平台数据进行查询分析,每位业务人员都需要掌握 SQL,导致学习成本高、上手难度大;
固定看板(Dashboard) : 技术人员基于常规业务开发制作数据看板,虽然能够简化业务分析师查询的过程,但是看板制作成本高且灵活度低,当面对复杂的用户问题时,看板无法及时调整以满足需求变更;
定制分析工具: 基于特定的业务需求,技术人员需要定制化开发产品分析工具,整体开发成本过高,且单一的开发工具不具备通用性,随着工具数量增加,操作介面变得散乱,从而降低业务效率;
人工跑数: 当以上三个场景都无法满足业务需求时,业务分析师需要向技术人员提需求进行人工跑数,沟通成本过高、整体解决效率低下。
SelectDB 的解决方案
面对经典方案中的落地难点,我们的总体解决思路是将以上四大挑战逐一拆解,通过组件叠加分阶段完善大模型 + OLAP 架构构建,最终实现全新的交互问答服务模式,接下来我们将介绍各阶段挑战对应的解决方案。
01 增加语义层:处理复杂数据问题
为了解决复杂数据处理问题,我们在大模型与 OLAP 中间增加 Semantic Layer(以下简称语义层)。
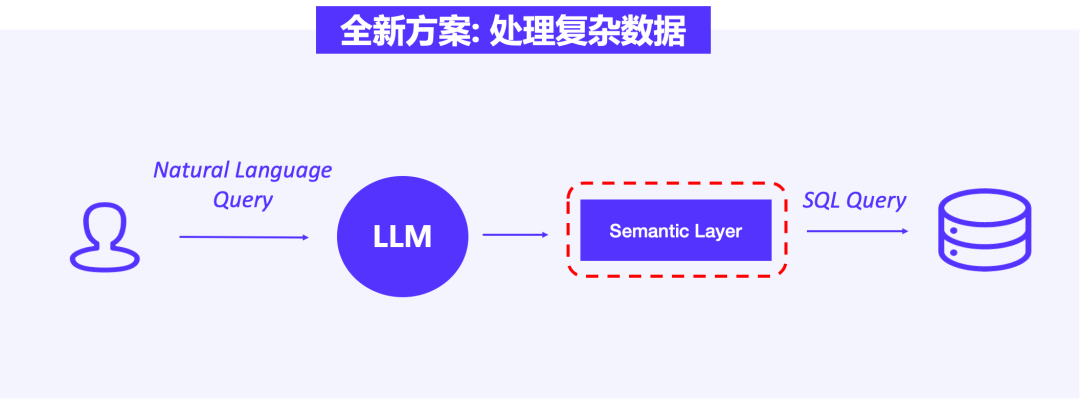
一方面语义层作为连接技术与业务之间的转换桥梁,能够将数据字段翻译为业务用户的术语,使业务知识作为额外的抽象层。通过语义层,业务分析师不需要在定义指标后存储于 OLAP 数仓中,能够直接在语义层中指定过滤条件,将所需指标筛选后生成 SQL 语句并在 OLAP 中进行字段查询。这意味着,业务分析师能够把多源数据按照需求定义成语义信息并形成语义标准,有效解决了多种指标、多类维度计算口径不统一的挑战。
另一方面语义层能够针对业务计算逻辑,进行语义加工、描述、关联和运算。语义层在过滤数据后,能够屏蔽由表关联所产生的复杂指标计算公式,将多表 Join 场景进行拆解、转化,形成较为简单的单表查询,以提升语义转化的准确性。
02 设定人工经验:处理模型效率问题
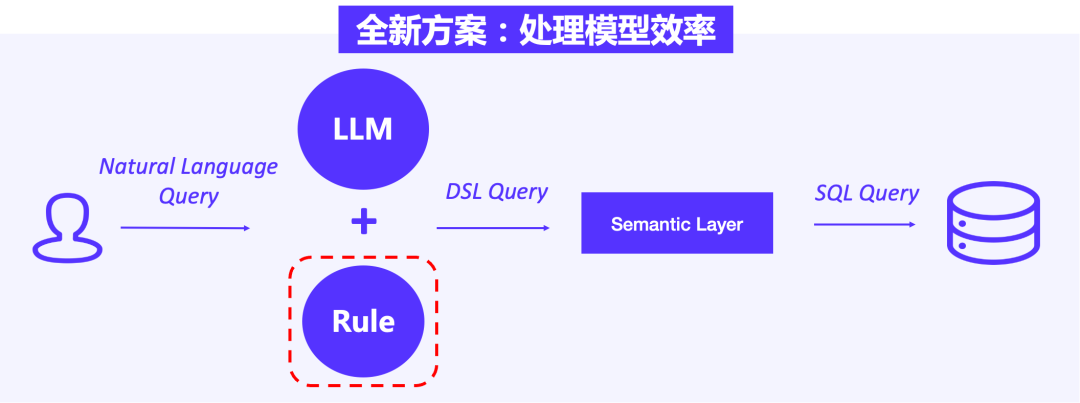
针对模型效率问题,我们的解决思路是对指标计算、明细查询、人群圈选等查询场景进行复杂度判定,将简单查询场景直接跳过大模型解析的步骤,进入底层 OLAP 进行处理分析,使大模型更加专注处理复杂查询场景。
为此,如上图所示我们在模型中添加人工经验判断。当业务分析师输入 “查询各大音乐平台收入”问题时,模型依据判定规则发现该场景只需要提供某个指标或几个维度即可完成,这时不需要将问题进入大模型解析,直接使用 OLAP 进行查询分析,能够有效缩短响应时间,提升结果反馈效率。此外,跳过大模型解析的步骤也能够节省 API 调用经费,解决平台使用成本升高的问题。
03 增加内容映射:处理私域知识问题
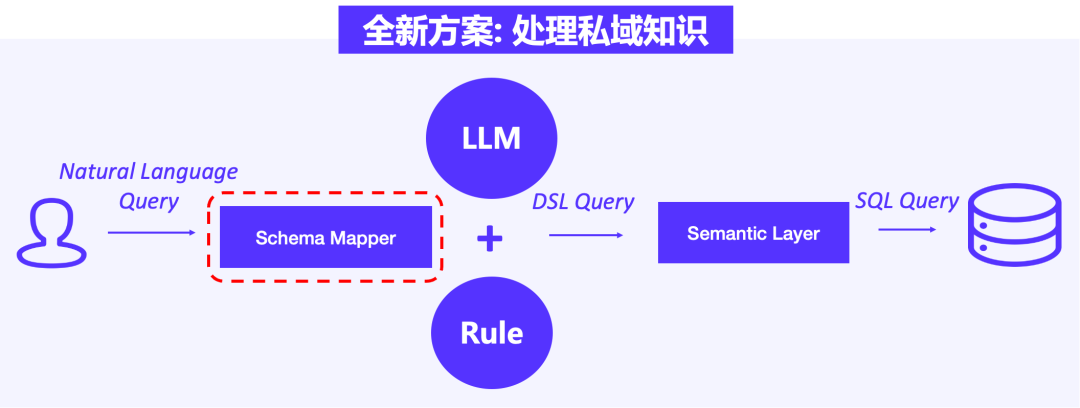
针对私域知识的问题,我们在大模型上游增加 Schema Mapper 、在外部建立业务知识库,将平台用户的问题与知识库进行连接,通过 Schema Mapper 判定是否存在部份文字能够与知识库内容匹配。如果匹配成功,大模型将进一步解析转化、OLAP 分析处理。Schema Mapper 与业务知识库的引入,有效解决了大模型对私域知识理解不足的问题,提升语言处理的效果。
目前,我们正在不断对 Schema Mapper 匹配准确性进行测试与优化,将知识库中的内容进行分类处理、字段评级等操作,同时将输入文本进行不同范围的内容映射(如全文本映射与模糊映射),通过映射结果来加强模型语义解析的能力。
04 插件接入:处理定制场景问题
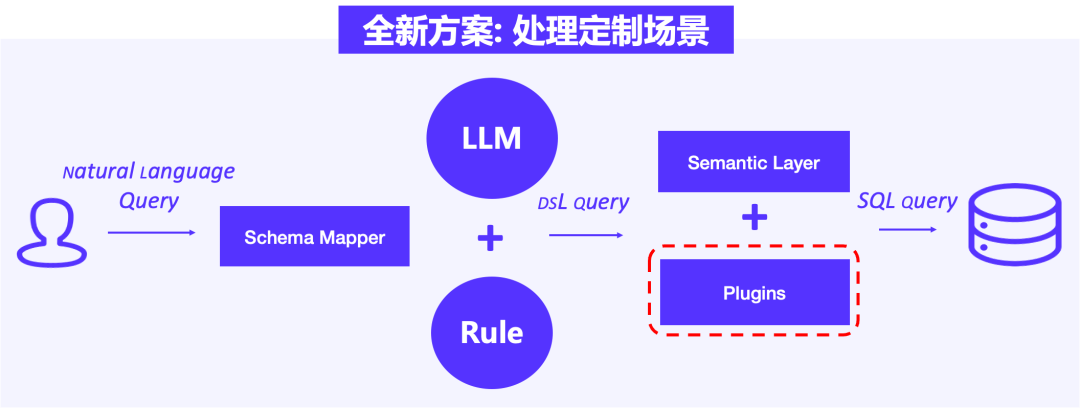
定制化场景主要指代业务范围之外的查询需求,需要将音乐内容数据与法律、政治、金融、监管等方面信息结合提供问答服务。通过增加插件,使平台用户能够访问实时更新且无法包含在训练数据或业务知识库中的信息,以实现定制化交互。
由于插件类型不同,模型接入方式也会有所不同,常见的接入方式主要分为两种:
1、Embedding 本地文本接入: 该方式首先对本地文档进行向量化处理,通过语义向量搜索,找到本地文档中相关或者相似的词语进行匹配,之后将文档内容注入大模型解析窗口中生成答案。这种方式非常适合业务分析师希望将音乐内容数据库与最新政策等一类较为私有的文件结合完成查询需求;
2、ChatGPT 第三方插件接入: 每款插件具备对应的 Prompt 与调用函数。业务人员在安装某款插件之后,在与模型对话中可以通过 Prompt 词触发函数开启调用。目前第三方插件类型丰富,涉及行业广泛,能够有效增加多元场景的处理与响应能力。
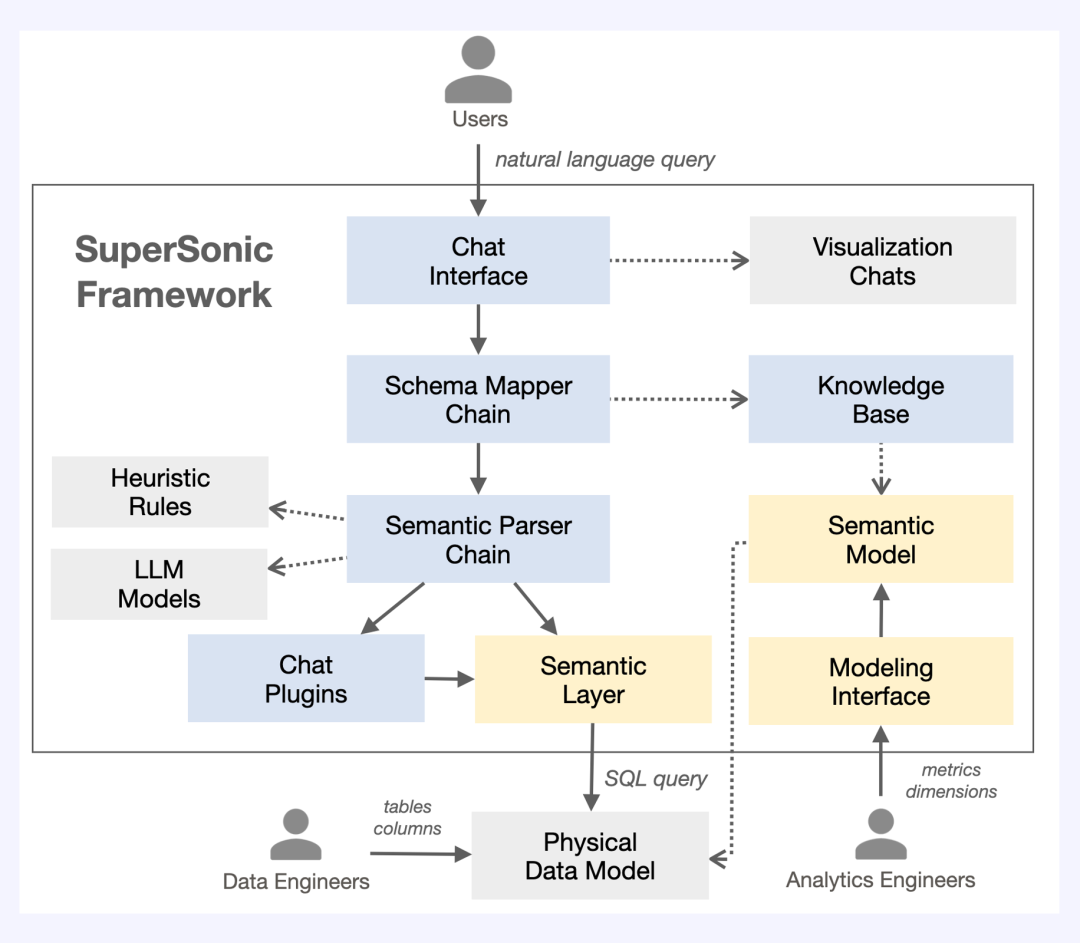
根据上述大模型 + OLAP 的四大解决方案进行了方案整合,以此进行框架设计并将其命名为超音数平台。大模型主要作用于自然语言与 SQL 分析语句的连接与转化,OLAP 引擎则作为数据存储与查询分析的核心基建。
点击查看完整版案例:当 Apache Doris 遇上大模型:探秘腾讯音乐如何基于大模型 + OLAP 构建智能数据服务平台
如果您的企业遇到了同样的困境可以来联系我们,我们(北京飞轮数据科技有限公司)是一家基于开源分析型数据库 Apache Doris 的商业化公司,由 Apache Doris 原创团队于2022年1月创建,公司总部位于北京,面向全球提供实时数据仓库的产品与解决方案,满足各类场景的实时数据分析需求。
飞轮科技的创始团队来自于原百度智能云初创人员和 Apache Doris 项目核心成员,公司 70% 员工为技术人员,且均来自于全球顶级数据库、云计算和互联网企业,拥有深厚的技术研发和服务经验。公司成立一年多,累计获得来自 IDG 资本、红杉中国和襄禾资本等投资机构近 10 亿元人民币融资,并在2022、2024年分别登顶全球分析型数据库测评榜单 ClickBench,在多种场景下,性能全球排名第一。
