导读:Cisco WebEx 早期数据平台采用了多系统架构(包括 Trino、Pinot、Iceberg 、 Kyuubi 等),面临架构复杂、数据冗余存储、运维困难、资源利用率低、数据时效性差等问题。因此,引入 Apache Doris 替换了 Trino、Pinot 、 Iceberg 及 Kyuubi 技术栈,依赖于 Doris 的实时数据湖能力及高性能 OLAP 分析能力,统一数据湖仓及查询分析引擎,显著提升了查询性能及系统稳定性,同时实现资源成本降低 30%。
WebEx 是 Cisco 推出的远程、实时的网络会议平台。全球财富 500 强公司中约有 95% 的公司采用 WebEx 来作为视频会议工具,日均会议次数突破 150 万次,全球业务市场超过 160 个。随着市场规模的扩大及使用者持续增加,亟需一个数据平台提供全面的数据及处理分析,以支持故障排查、批量和实时的分析、BI 和大模型的应用、可观测性与数据治理等需求。
在此背景下,WebEx 数据平台从早期的多系统架构(包括 Trino、Pinot、Iceberg 、 Kyuubi 等)改造为基于 Apache Doris 的统一架构。使用 Doris 替换了 Trino、Pinot 、 Iceberg 及 Kyuubi 技术栈,统一数据湖仓及查询分析引擎。显著提升了查询性能及系统稳定性,同时实现资源成本降低 30%。新架构目前已应用于 CCA Peak Ports 项目、Dashboard 系统、统一认证授权等业务场景中。
早期架构及痛点
为适配复杂的业务需求,早期架构融合了多种技术栈。数据源通过 Kafka 进行数据抽取,由 UDP 调度系统(Unified Data Platform:调度 ETL/Spark/Flink 等数据处理任务的平台)将数据调度并存储到湖仓层的 Iceberg 中。Trino、Kyuubi 收到查询请求后提供查询服务,Pinot 主要用于 OLAP 分析。
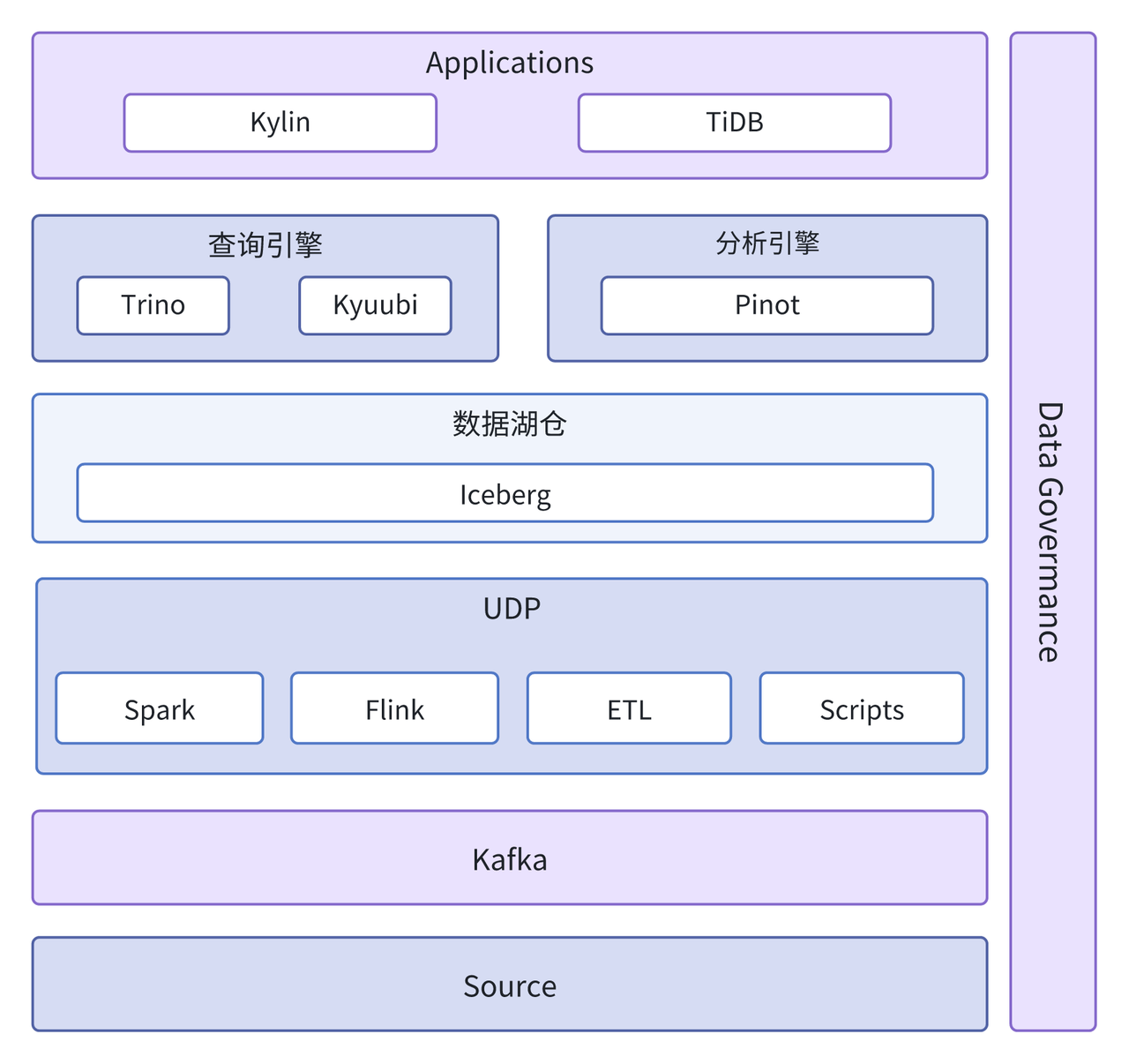
由于该架构技术栈多样、结构复杂,在实际应用中引发了诸多问题:
- 运维困难: 多种数据库并存,运维管理工作也变得繁琐且困难。
- 资源利用率低:数据冗余严重,查询入口不统一,难以实现 CPU 和内存资源的高效利用。
- 数据一致性问题频发:多个技术栈中数据独立计算,计算口径不一致,常常引发用户负面反馈。
- 数据治理挑战: 元数据来源多样且格式各异,数据的准确性和一致性难以保障,直接影响了数据治理的效率。
基于 Apache Doris 统一技术栈
01 技术选型
因此迫切需要统一技术栈、降低技术架构的复杂度,同时希望实现性能提升、降低使用成本及简化运维。经过调研,他们发现 Apache Doris 具备的特性能够很好满足这些需求。具体如下:
- 数据湖能力: Apache Doris 支持 Multi-Catalog 多源数据目录,通过扩展 Catalog 和存储插件,无需将数据物理集中至统一的存储空间,仅借助 Apache Doris 即可实现多个异构数据源的统一联邦分析。目前支持 Hive、 Iceberg、Hudi、Paimon、Elasticsearch、MySQL、Oracle、SQL Server 等主流数据湖、数据库的连接访问。
- 实时写入: Doris 支持直接从 Kafka 等数据源进行数据订阅和导入,避免了复杂的 ETL 过程,提高了数据的实时性。
- 简单易用:Doris 提供统一的架构,减少了对多种技术栈的依赖,降低了系统的复杂性,运维难度及工作量均较低,结合多数据源目录,可实现低成本快速迁移。
- 高性能查询: Doris 采用列式存储和高性能查询引擎,能够快速处理大规模数据集,实现低延迟的查询响应。
02 统一数据湖仓及查询分析引擎
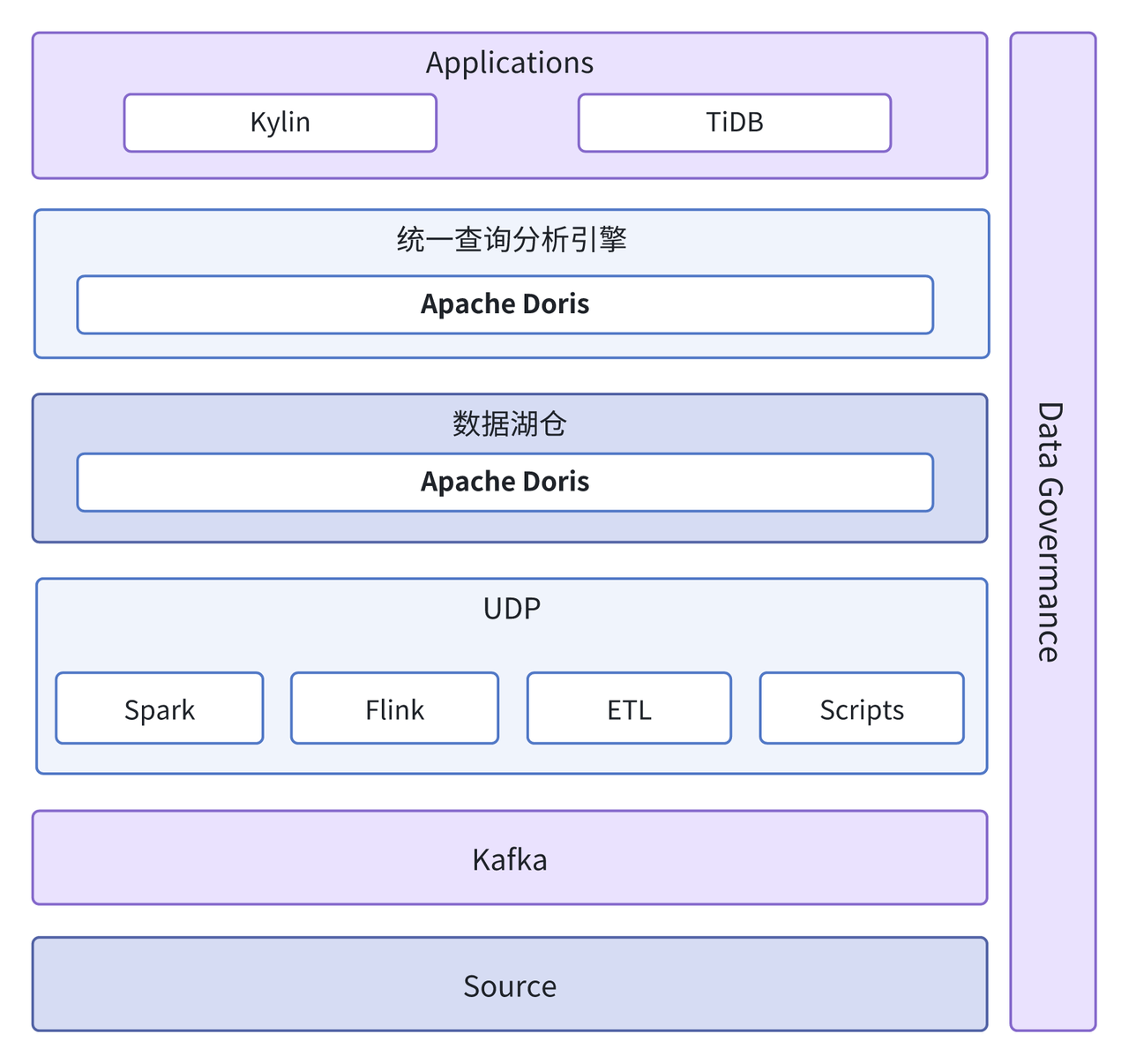
基于上述优势,采用 Apache Doris 替换了原先数据湖仓 Iceberg ,统一了查询引擎 Trino、Kyuubi 以及 OLAP 分析引擎 Pinot。依托于 Doris Multi-Catalog 数据湖能力,无需进行数据传输即可直接查询底层引擎中数据;借助其 OLAP 能力,显著提升了数据分析的效率。
具体收益如下:
- 降低架构复杂性:由 Doris 替换多个技术栈,简化系统架构,减少组件间的依赖和集成工作。
- 简化 ETL 流程:原先数据传输需要经过一系列 ETL 与 Spark Load 转换,流程复杂且需要维护大量计算任务。而 Doris Routine Load 能够直接订阅 Kafka 数据,简化了 ETL 流程。
- 提升资源利用率: 1 个 Doris 集群即可替代原来多个集群,数据无需在多个数据库冗余存储,资源利用率大幅提升,成本节约 30%。
- 降低运维及使用成本:架构及 ETL 流程的简化,大幅降低潜在故障点的发生次数,系统稳定性得到较大的提升。
Apache Doris 架构下的业务改造实践
01 报表生成耗时缩短 50%
CCA Peak Ports 项目用于在基于 Peak Ports 套餐的计费模式下,计算 WebEx 与 Partner 之间的对账报表。该项目所采用的技术栈较为传统,数据处理链路较长,系统维护工作量较大,因此作为第一批基于 Doris 改造项目。
原方案:
- 首先,依赖于 Oracle 数据库中的原始表作为数据源,通过一系列存储过程进行计算,生成中间结果。
- 接着,Java 编写的定时任务进一步处理中间结果,并最终写入 Kafka 消息队列。
- 最后,通过 Spark Job 将 Kafka 中数据同步到 Iceberg 中提供报表服务。
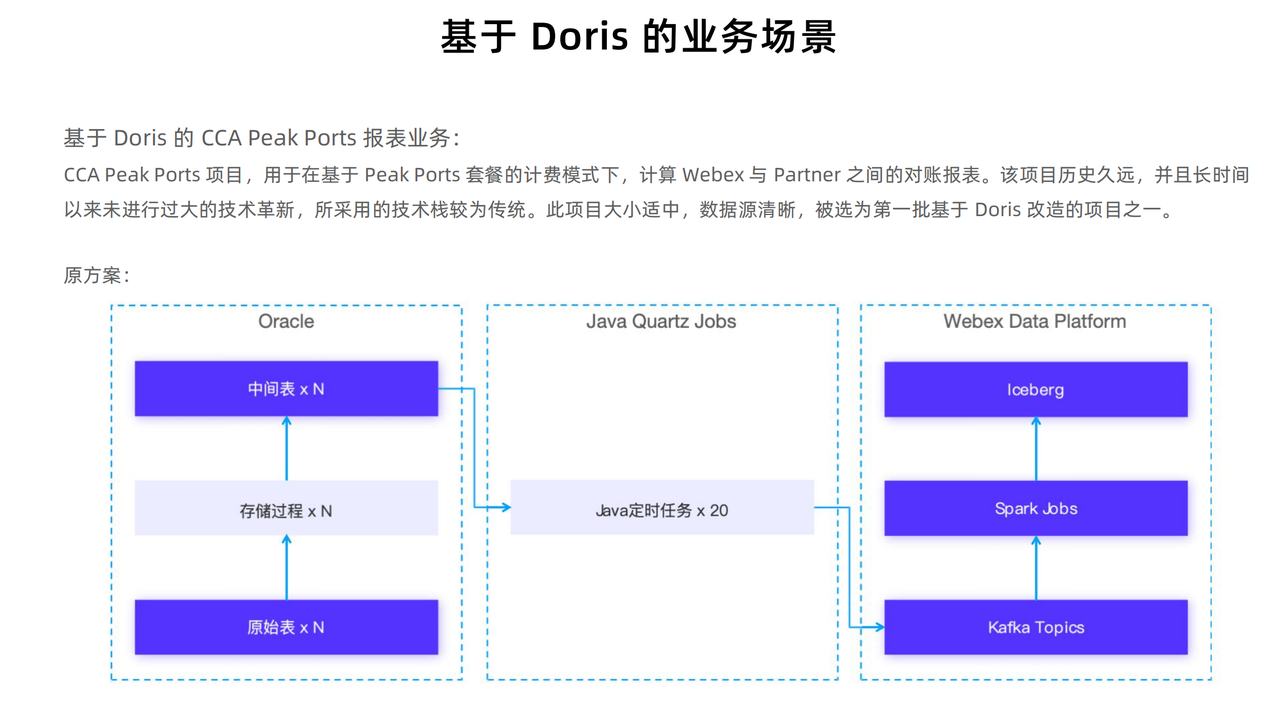
在上述流程中,一旦数据计算过程中出现问题,排查和调试就会变得相当复杂和繁琐。特别是在 Oracle 存储过程的调试,往往不够直观和便捷,增加了解决问题的难度。同时也由于该流程过于复杂,对数据的实时性也产生了一定的影响。
新方案:
基于 Doris 进行改造,将 Oracle 的存储过程改造到 Spark 与 Doris UDF 中,并使用 Doris 替换了 Iceberg,借助 Doris 高效存储和分析能力直接提供数据服务。具体流程如下:
- 首先,所有数据已预先存储在 Kafka 中。
- 接着,通过 Doris 提供的 Doris-Kafka-Connector 插件,通过 Routine Load 可直接将 Kafka Topics 中数据写入 Doris 中,并将数据整合到明细表中构成 DWD 层。
- 最后,提前部署好的 Spark 作业会对明细数据进行深入的分析与处理,最终将结果写入 DWS 层,由 Doris 提供业务侧数据分析和报表生成的需求。
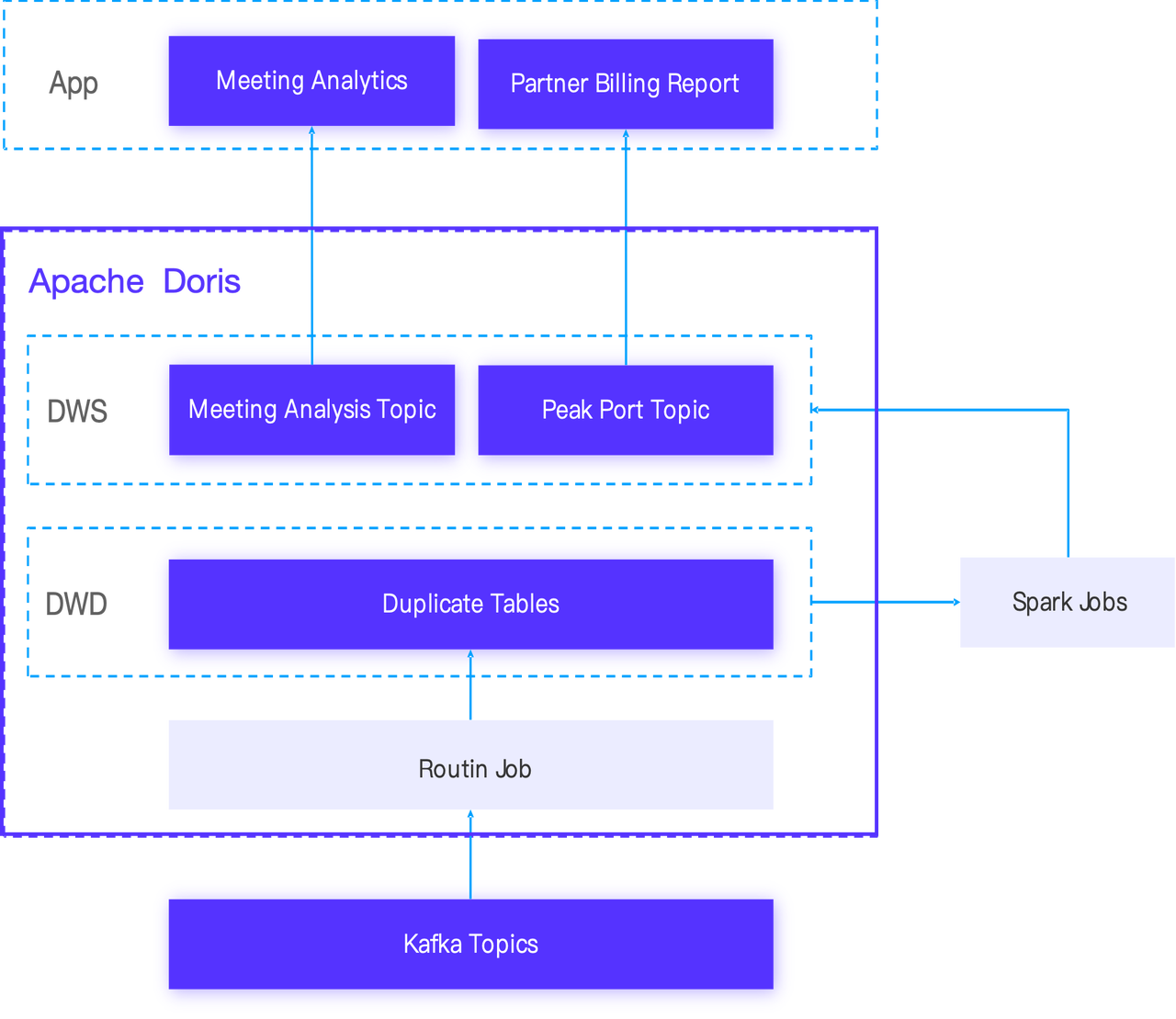
CCA Peak Ports 项目在基于 Doris 的改造下,整体技术栈风格更为统一,简化了数据处理链路,数据处理更加高效。 在时效性方面,报表更新周期从 T+2 缩短至 T+1;在查询效率方面,报表生成时间由原先 10 分钟缩短至 5 分钟,查询效率至少提升 1 倍多。
02 数据处理流程大幅简化
Dashboard 系统主要用于展示数据治理的全貌,特别是关于 WebEx 的数据资产概况和分析指标,为管理团队的业务决策提供坚实的数据支撑。
在早期数据治理平台中,依赖 Spark 定期任务提取数据进行 Schema 分析和 Lineage 分析。分析后的结果发送至 Kafka,随后由 Pinot 实时摄取,以便后续的处理展示。这种分散的处理方式可能使得数据治理的整体效率和效果受到限制。不同组件之间的数据交换和同步可能会带来额外的开销和延迟,同时也不利于数据的统一管理和优化。
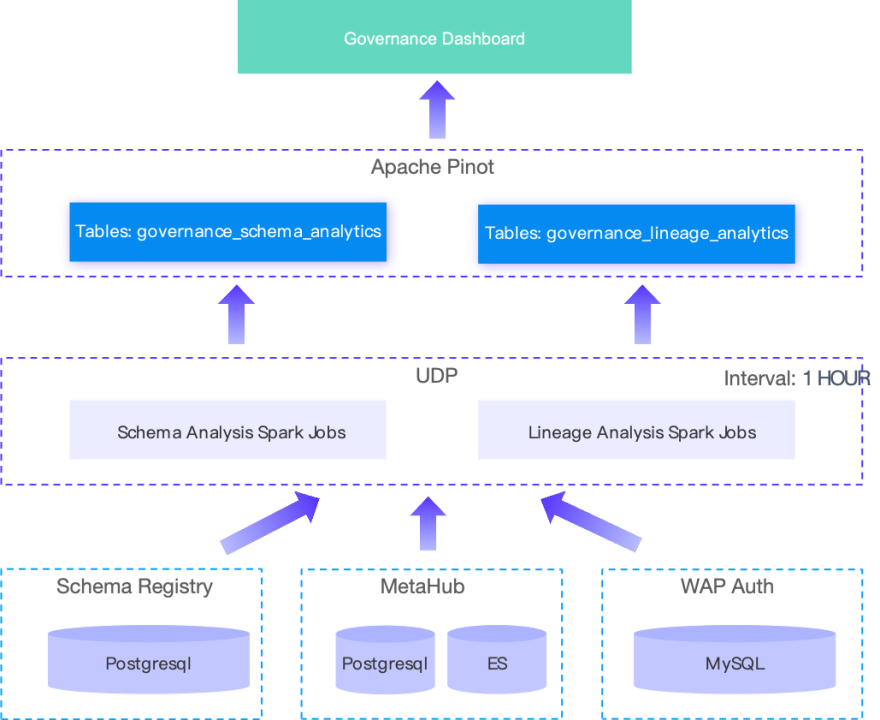
为解决该问题,使用 Doris 替换了 Pinot ,并基于 Doris Multi-Catalog 能力对底层引擎分别建立了 Catalog,使用 Doris 定时任务抽取引擎中数据。抽取的数据被写入上层的主键模型和聚合模型表中。依赖于 Doris SQL 抽取能力以及其提供的数据模型,完全能够满足 Governance Dashboard 的数据需求。
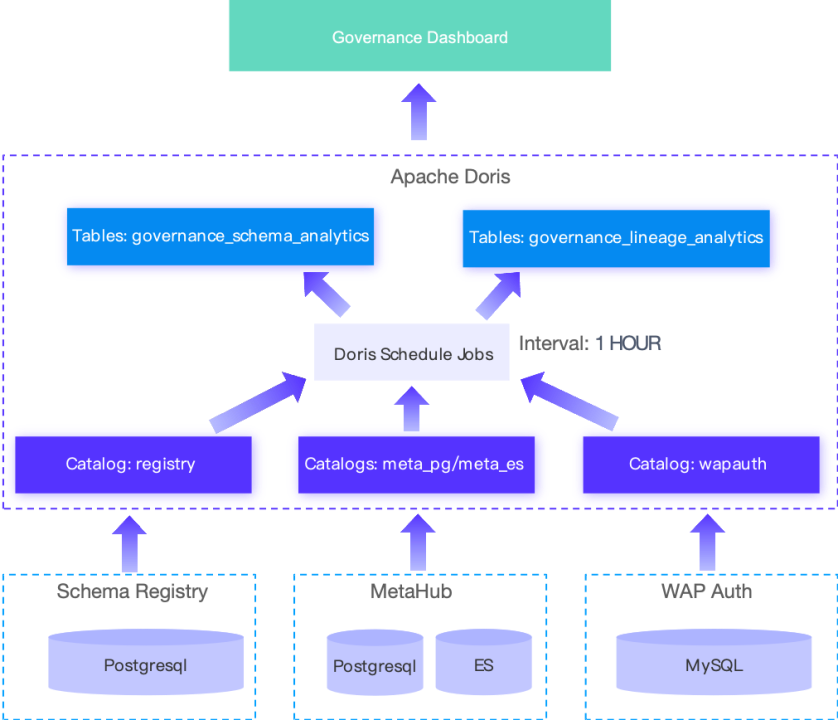
这一方案的节省了原先 11 个 Spark 作业的维护工作,整个 Data Pipeline 都能够在 Doris 中创建和管理,处理流程更加清晰、简单、高效。同时,降低了 UDP 对 CPU 和内存资源的依赖,避免了偶发的因资源不足导致 Job 无法启动的问题。此外,尽管 Doris 相比 Pinot 查询性能并无巨大提升,但在执行相同的查询时,Doris 消耗的资源更少,更能保证查询正常返回。
03 统一查询服务,降低多平台管理难度
在早期认证授权场景中,面临查询入口不统一、用户查询复杂度各异的挑战。这不仅会导致资源利用率低下,还可能引发单个资源密集型查询对其他用户查询性能的严重干扰。
除上述问题外,从用户角度来说,他们需要管理多个系统之间的链接关联,加之各平台密码更新周期的不统一,反复申请认证授权等问题也消耗了大量的时间与精力。
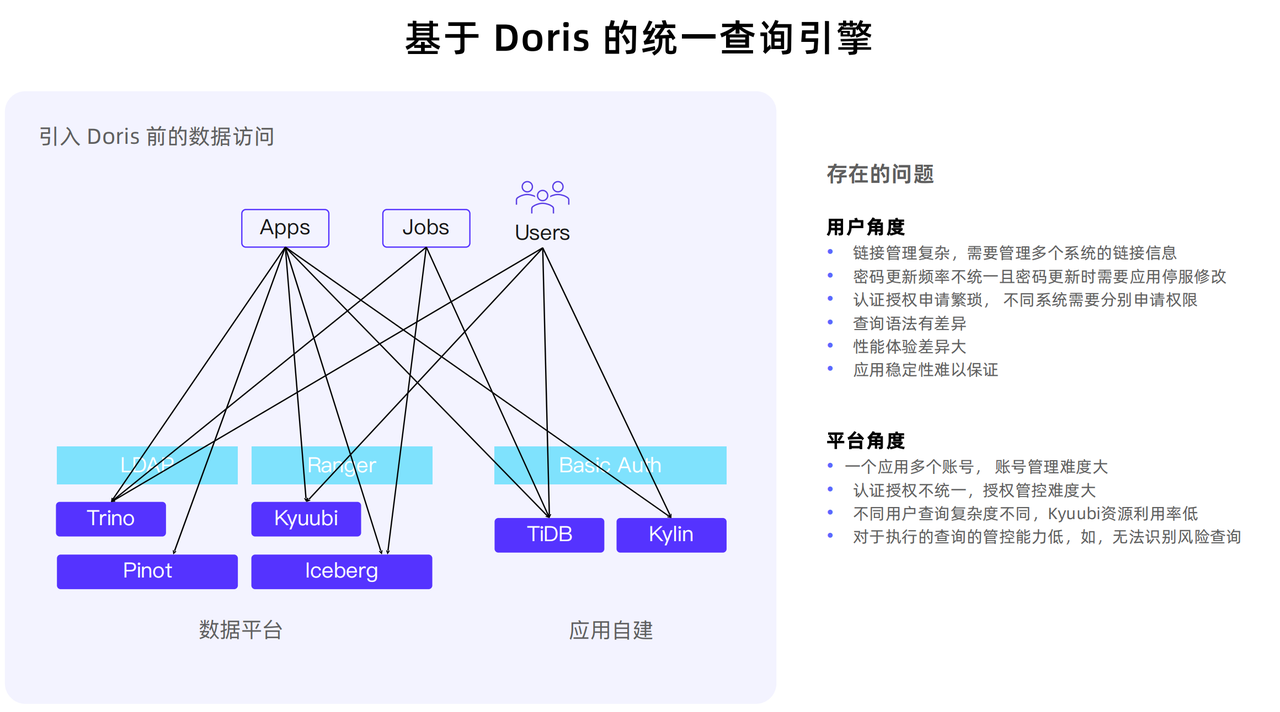
为了解决这些问题,结合 Doris 实现了统一查询服务,整体框架下图所示:
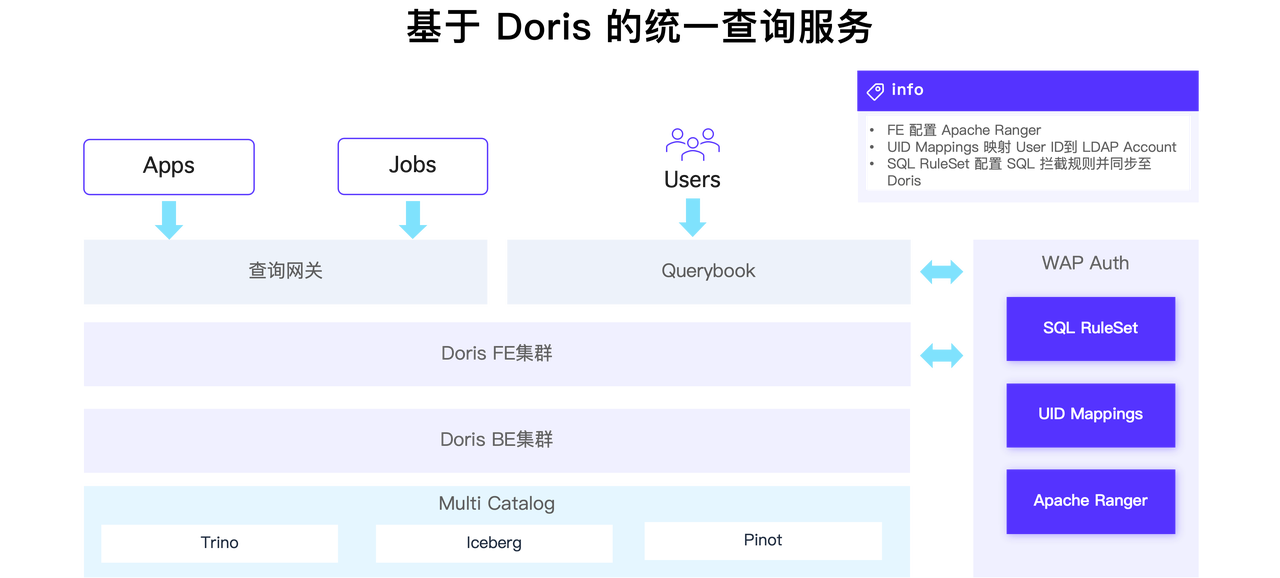
使用 Doris 替换实现了统一的查询服务,依托于 Doris Multi-Catalog 能力,对底层 Trino、Iceberg 和 Pinot 引擎构建 Catalog。 所有应用和作业可以通过查询网关接入 Doris,直接对底层引擎中数据进行查询。
为便于用户使用,还为所有用户创建了 Query Book 服务,以便统一访问湖中数据。此外,结合 Apache Ranger 构建了 Web Auth 服务,将统一认证授权同步至 Doris。原先,用户和平台管理员原先需要在 3 个不同的平台(LDAP/Ranger/DB)中申请和审批权限,现在只需访问 WAP Auth 即可,降低多平台管理负担。还在 Web Auth 中开发了 SQL 规则集模块,支持将规则集的定义同步到 Doris,对高风险 SQL 进行拦截,避免潜在资源滥用。
基于 Doris 的数据治理
作为一个在全球范围内分布应用的在线会议产品,WebEx 面临各个国家、各个地区不同隐私数据保护的法案和相关要求,所以数据治理环节至关重要。
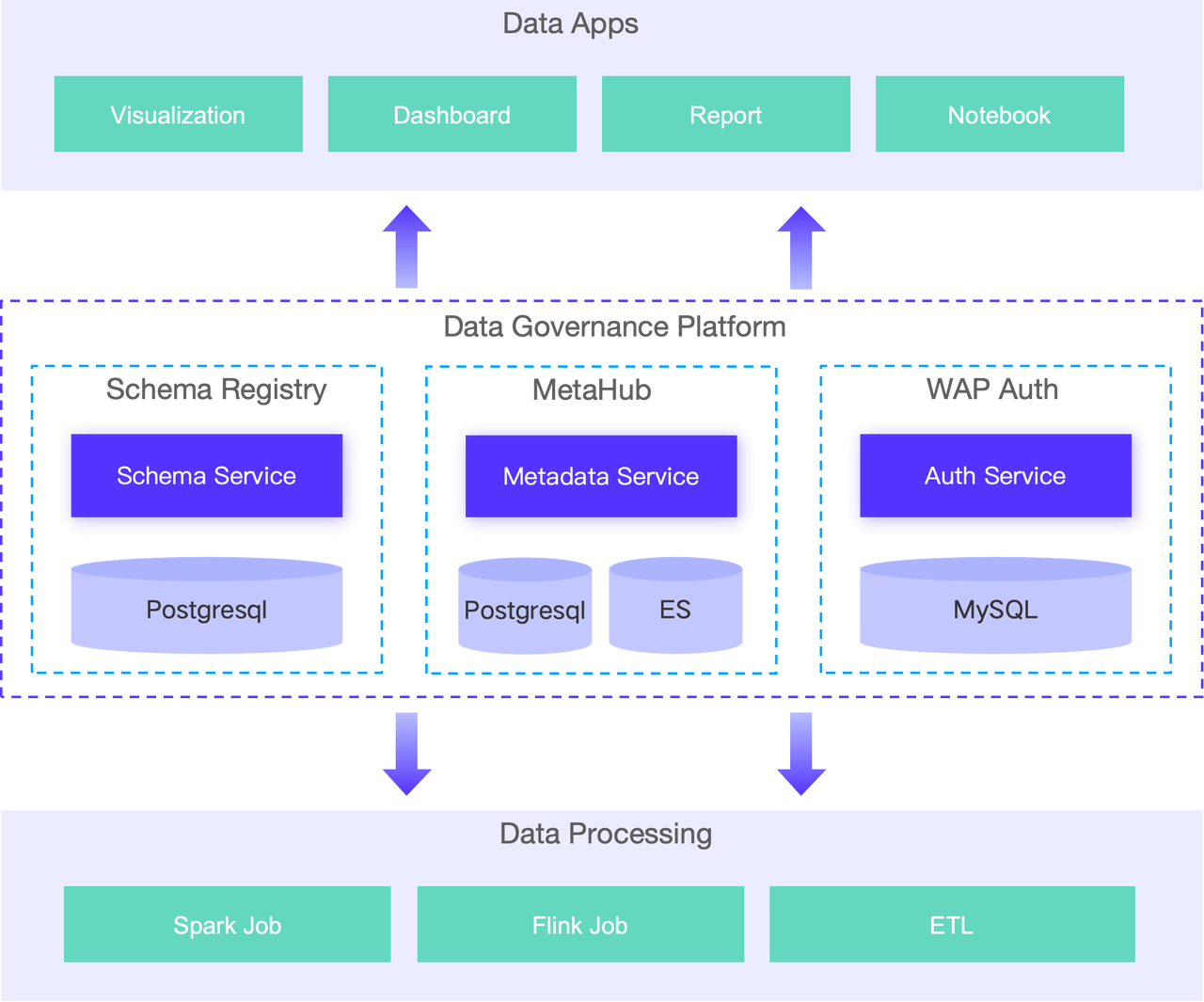
为确保企业数据资产的质量、安全和可用性,需要对 WebEx Data Platform 进行数据治理。在引入 Apache Doris 后,也需将其纳入数据治理体系中。这涉及到元数据融合、数据授权与审计、合规检查、质量检查的融合。为支撑这些融合点,需要构建元数据流、血缘数据流、审查数据流。
01 元数据流
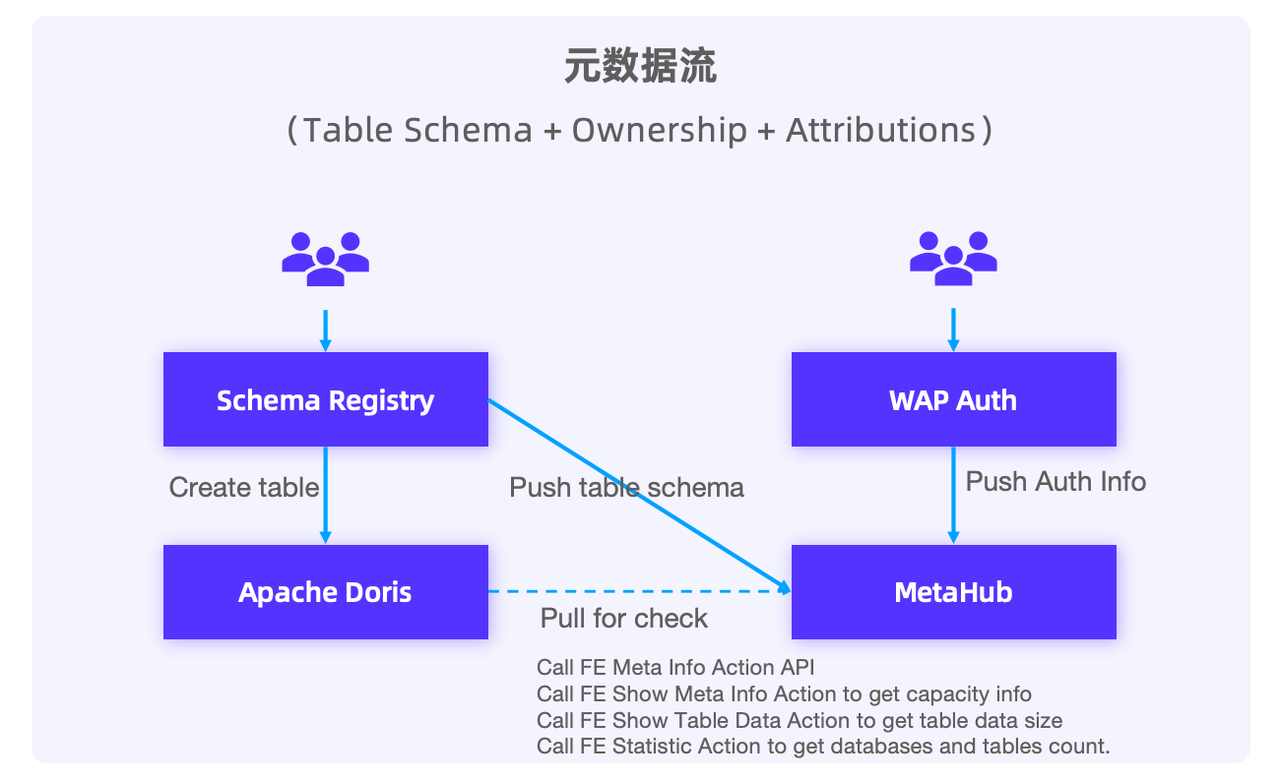
元数据流作用在于确保元数据顺利同步。Schema Registry 可轻松地将元数据推送至 MetaHub,实现集中存储与管理。Doris 提供了丰富的元数据 API 接口,能够无缝接入大量有价值的元数据,增强 MetaHub 的数据完整性和实用性。
02 血缘数据流
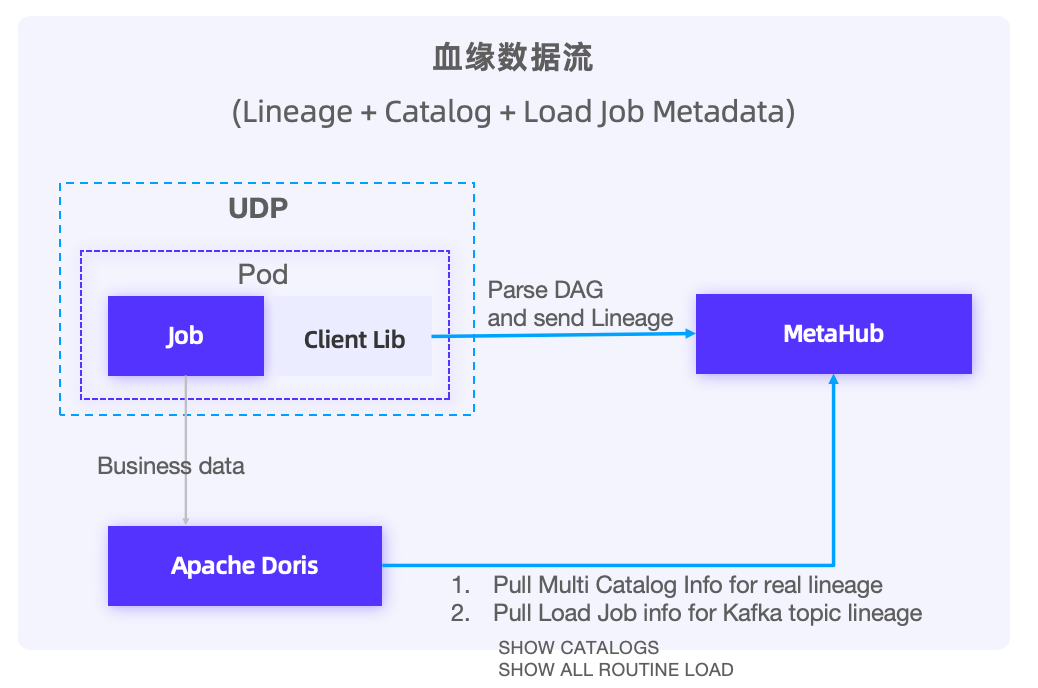
血缘数据流整合有两部分:
- 静态信息拉取:从 Doris 数据库提取定义好的作业信息(如 Routine Job),反映数据从 Kafka 流向 Doris 表的路径。同时获取 Catalog 信息(部分 Catalog 条目对应外部表,Table 直接存储在 Doris 中),以确保捕获外部表的真实血缘关系。
- 动态数据血缘生成:当新 Job 读取或写入 Doris 时,生成新的数据血缘关系。为管理动态血缘开发了 Client Library,在平台调度 Job 时,Library 以 Sidecar 的形式注入 Job ,Client Library 解析 Job 的 DAG,并基于此生成数据血缘信息,并将信息发送到 MetaHub。
通过结合静态和动态数据血缘的方法,能够全面追踪数据的流动和变化,从而为数据治理和分析提供坚实的基础。
03 审查数据流

数据流审查主要集中在数据审计、合规性检查和质量监控三个方面。在数据审计方面,直接从 Doris 系统中提取 Audit_log 数据,实现高效审计。在合规性和质量监控上,采用定时任务主动扫描并验证 Doris 中的数据,以确保其合规性和质量达标。
在实时生成并写入 Doris 新数据时,可以利用 Client Library 提供的嵌入式功能,持续监测新生成或正在处理的数据,这一机制不仅提升了数据处理效率,还增强了数据管理的安全性与可靠性。
结束语
截至目前,WebEx 数据平台所部署的 Doris 集群近 5 个,总节点数十台。当前已支持在线服务的平均每日查询总数量已超过 10 万,存储总量 40TB+,实时导入的日增数据量高达 5TB+。Doris 的引入不仅带来了诸多降本增效的助力,也驱动其在更大范围内的业务发展探索改造思路与方向:
- 扩大 Doris 应用范围: 逐步迁移更多数据湖仓中的业务与数据应用层 App 进入 Doris。
- 增强数据平台功能与性能: 基于 Doris 构建高性能数据分析平台,逐步替代应用自建的分析性存储方案,如 TiDB,Kylin 等。
- 探索更多应用场景: 探索 AI on Doris 以及 Doris on Paimon 的场景。



